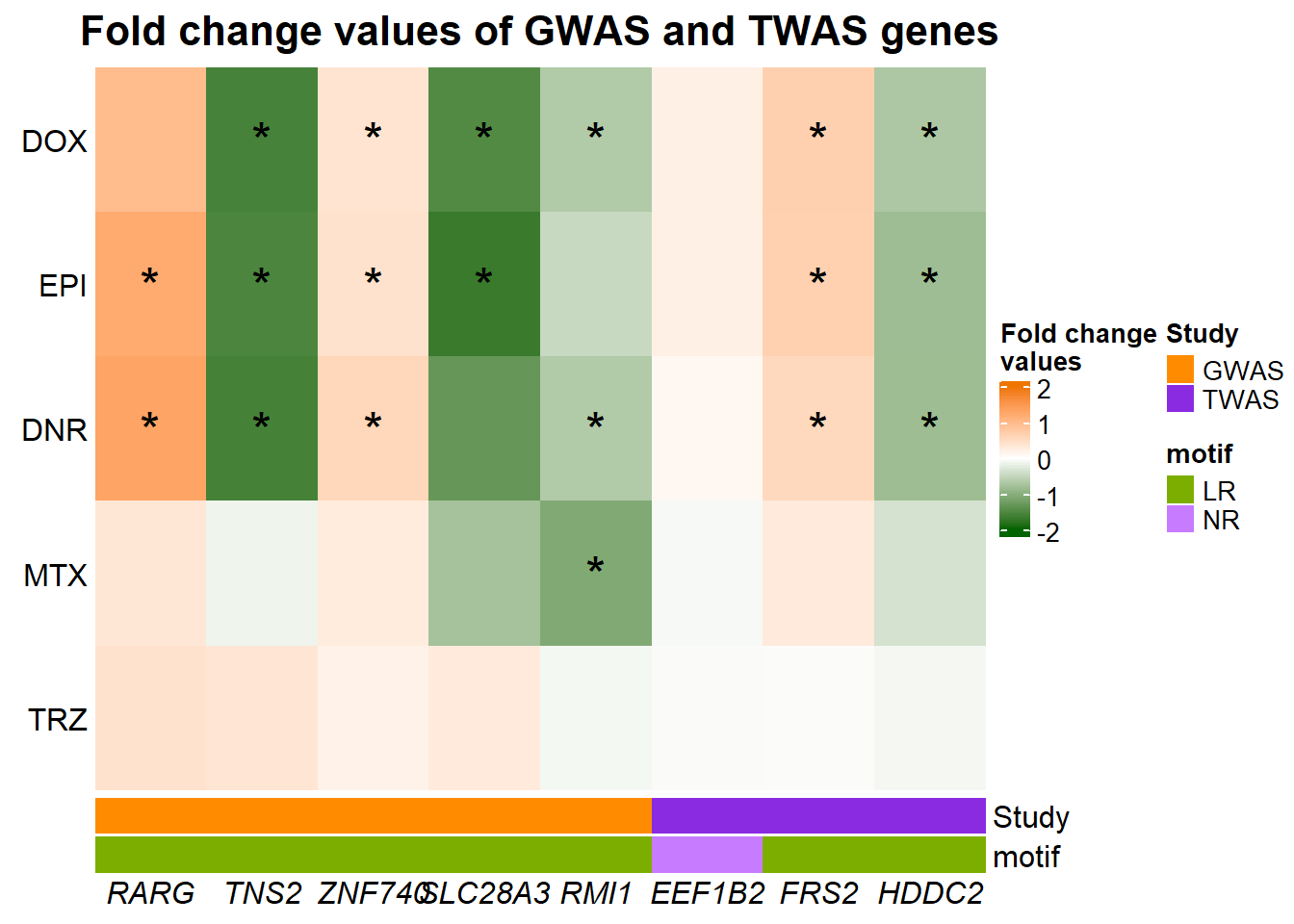
Figure 9: Genes in AC toxicity-associated loci respond to TOP2i
ERM
2023-09-28
Last updated: 2023-09-28
Checks: 7 0
Knit directory: Cardiotoxicity/
This reproducible R Markdown analysis was created with workflowr (version 1.7.1). The Checks tab describes the reproducibility checks that were applied when the results were created. The Past versions tab lists the development history.
Great! Since the R Markdown file has been committed to the Git repository, you know the exact version of the code that produced these results.
Great job! The global environment was empty. Objects defined in the global environment can affect the analysis in your R Markdown file in unknown ways. For reproduciblity it’s best to always run the code in an empty environment.
The command set.seed(20230109) was run prior to running
the code in the R Markdown file. Setting a seed ensures that any results
that rely on randomness, e.g. subsampling or permutations, are
reproducible.
Great job! Recording the operating system, R version, and package versions is critical for reproducibility.
Nice! There were no cached chunks for this analysis, so you can be confident that you successfully produced the results during this run.
Great job! Using relative paths to the files within your workflowr project makes it easier to run your code on other machines.
Great! You are using Git for version control. Tracking code development and connecting the code version to the results is critical for reproducibility.
The results in this page were generated with repository version 3989a79. See the Past versions tab to see a history of the changes made to the R Markdown and HTML files.
Note that you need to be careful to ensure that all relevant files for
the analysis have been committed to Git prior to generating the results
(you can use wflow_publish or
wflow_git_commit). workflowr only checks the R Markdown
file, but you know if there are other scripts or data files that it
depends on. Below is the status of the Git repository when the results
were generated:
Ignored files:
Ignored: .RData
Ignored: .Rhistory
Ignored: .Rproj.user/
Ignored: data/41588_2018_171_MOESM3_ESMeQTL_ST2_for paper.csv
Ignored: data/Arr_GWAS.txt
Ignored: data/Arr_geneset.RDS
Ignored: data/BC_cell_lines.csv
Ignored: data/BurridgeDOXTOX.RDS
Ignored: data/CADGWASgene_table.csv
Ignored: data/CAD_geneset.RDS
Ignored: data/CALIMA_Data/
Ignored: data/Clamp_Summary.csv
Ignored: data/Cormotif_24_k1-5_raw.RDS
Ignored: data/Counts_RNA_ERMatthews.txt
Ignored: data/DAgostres24.RDS
Ignored: data/DAtable1.csv
Ignored: data/DDEMresp_list.csv
Ignored: data/DDE_reQTL.txt
Ignored: data/DDEresp_list.csv
Ignored: data/DEG-GO/
Ignored: data/DEG_cormotif.RDS
Ignored: data/DF_Plate_Peak.csv
Ignored: data/DRC48hoursdata.csv
Ignored: data/Da24counts.txt
Ignored: data/Dx24counts.txt
Ignored: data/Dx_reQTL_specific.txt
Ignored: data/EPIstorelist24.RDS
Ignored: data/Ep24counts.txt
Ignored: data/Full_LD_rep.csv
Ignored: data/GOIsig.csv
Ignored: data/GOplots.R
Ignored: data/GTEX_setsimple.csv
Ignored: data/GTEX_sig24.RDS
Ignored: data/GTEx_gene_list.csv
Ignored: data/HFGWASgene_table.csv
Ignored: data/HF_geneset.RDS
Ignored: data/Heart_Left_Ventricle.v8.egenes.txt
Ignored: data/Heatmap_mat.RDS
Ignored: data/Heatmap_sig.RDS
Ignored: data/Hf_GWAS.txt
Ignored: data/K_cluster
Ignored: data/K_cluster_kisthree.csv
Ignored: data/K_cluster_kistwo.csv
Ignored: data/LD50_05via.csv
Ignored: data/LDH48hoursdata.csv
Ignored: data/Mt24counts.txt
Ignored: data/NoRespDEG_final.csv
Ignored: data/RINsamplelist.txt
Ignored: data/Seonane2019supp1.txt
Ignored: data/TMMnormed_x.RDS
Ignored: data/TOP2Bi-24hoursGO_analysis.csv
Ignored: data/TR24counts.txt
Ignored: data/TableS10.csv
Ignored: data/TableS11.csv
Ignored: data/TableS9.csv
Ignored: data/Top2biresp_cluster24h.csv
Ignored: data/Var_test_list.RDS
Ignored: data/Var_test_list24.RDS
Ignored: data/Var_test_list24alt.RDS
Ignored: data/Var_test_list3.RDS
Ignored: data/Vargenes.RDS
Ignored: data/Viabilitylistfull.csv
Ignored: data/allexpressedgenes.txt
Ignored: data/allfinal3hour.RDS
Ignored: data/allgenes.txt
Ignored: data/allmatrix.RDS
Ignored: data/allmymatrix.RDS
Ignored: data/annotation_data_frame.RDS
Ignored: data/averageviabilitytable.RDS
Ignored: data/avgLD50.RDS
Ignored: data/avg_LD50.RDS
Ignored: data/backGL.txt
Ignored: data/burr_genes.RDS
Ignored: data/calcium_data.RDS
Ignored: data/clamp_summary.RDS
Ignored: data/cormotif_3hk1-8.RDS
Ignored: data/cormotif_initalK5.RDS
Ignored: data/cormotif_initialK5.RDS
Ignored: data/cormotif_initialall.RDS
Ignored: data/cormotifprobs.csv
Ignored: data/counts24hours.RDS
Ignored: data/cpmcount.RDS
Ignored: data/cpmnorm_counts.csv
Ignored: data/crispr_genes.csv
Ignored: data/ctnnt_results.txt
Ignored: data/cvd_GWAS.txt
Ignored: data/dat_cpm.RDS
Ignored: data/data_outline.txt
Ignored: data/drug_noveh1.csv
Ignored: data/efit2.RDS
Ignored: data/efit2_final.RDS
Ignored: data/efit2results.RDS
Ignored: data/ensembl_backup.RDS
Ignored: data/ensgtotal.txt
Ignored: data/filcpm_counts.RDS
Ignored: data/filenameonly.txt
Ignored: data/filtered_cpm_counts.csv
Ignored: data/filtered_raw_counts.csv
Ignored: data/filtermatrix_x.RDS
Ignored: data/folder_05top/
Ignored: data/geneDoxonlyQTL.csv
Ignored: data/gene_corr_df.RDS
Ignored: data/gene_corr_frame.RDS
Ignored: data/gene_prob_tran3h.RDS
Ignored: data/gene_probabilityk5.RDS
Ignored: data/geneset_24.RDS
Ignored: data/gostresTop2bi_ER.RDS
Ignored: data/gostresTop2bi_LR
Ignored: data/gostresTop2bi_LR.RDS
Ignored: data/gostresTop2bi_TI.RDS
Ignored: data/gostrescoNR
Ignored: data/gtex/
Ignored: data/heartgenes.csv
Ignored: data/hsa_kegg_anno.RDS
Ignored: data/individualDRCfile.RDS
Ignored: data/individual_DRC48.RDS
Ignored: data/individual_LDH48.RDS
Ignored: data/indv_noveh1.csv
Ignored: data/kegglistDEG.RDS
Ignored: data/kegglistDEG24.RDS
Ignored: data/kegglistDEG3.RDS
Ignored: data/knowfig4.csv
Ignored: data/knowfig5.csv
Ignored: data/label_list.RDS
Ignored: data/ld50_table.csv
Ignored: data/mean_vardrug1.csv
Ignored: data/mean_varframe.csv
Ignored: data/mymatrix.RDS
Ignored: data/new_ld50avg.RDS
Ignored: data/nonresponse_cluster24h.csv
Ignored: data/norm_LDH.csv
Ignored: data/norm_counts.csv
Ignored: data/old_sets/
Ignored: data/organized_drugframe.csv
Ignored: data/plan2plot.png
Ignored: data/plot_intv_list.RDS
Ignored: data/plot_list_DRC.RDS
Ignored: data/qval24hr.RDS
Ignored: data/qval3hr.RDS
Ignored: data/qvalueEPItemp.RDS
Ignored: data/raw_counts.csv
Ignored: data/response_cluster24h.csv
Ignored: data/sigVDA24.txt
Ignored: data/sigVDA3.txt
Ignored: data/sigVDX24.txt
Ignored: data/sigVDX3.txt
Ignored: data/sigVEP24.txt
Ignored: data/sigVEP3.txt
Ignored: data/sigVMT24.txt
Ignored: data/sigVMT3.txt
Ignored: data/sigVTR24.txt
Ignored: data/sigVTR3.txt
Ignored: data/siglist.RDS
Ignored: data/siglist_final.RDS
Ignored: data/siglist_old.RDS
Ignored: data/slope_table.csv
Ignored: data/supp10_24hlist.RDS
Ignored: data/supp10_3hlist.RDS
Ignored: data/supp_normLDH48.RDS
Ignored: data/supp_pca_all_anno.RDS
Ignored: data/table3a.omar
Ignored: data/testlist.txt
Ignored: data/toplistall.RDS
Ignored: data/trtonly_24h_genes.RDS
Ignored: data/trtonly_3h_genes.RDS
Ignored: data/tvl24hour.txt
Ignored: data/tvl24hourw.txt
Ignored: data/venn_code.R
Ignored: data/viability.RDS
Untracked files:
Untracked: .RDataTmp
Untracked: .RDataTmp1
Untracked: .RDataTmp2
Untracked: .RDataTmp3
Untracked: 3hr all.pdf
Untracked: Code_files_list.csv
Untracked: Data_files_list.csv
Untracked: Doxorubicin_vehicle_3_24.csv
Untracked: Doxtoplist.csv
Untracked: EPIqvalue_analysis.Rmd
Untracked: GWAS_list_of_interest.xlsx
Untracked: KEGGpathwaylist.R
Untracked: OmicNavigator_learn.R
Untracked: SigDoxtoplist.csv
Untracked: analysis/ciFIT.R
Untracked: analysis/export_to_excel.R
Untracked: cleanupfiles_script.R
Untracked: code/biomart_gene_names.R
Untracked: code/constantcode.R
Untracked: code/corMotifcustom.R
Untracked: code/cpm_boxplot.R
Untracked: code/extracting_ggplot_data.R
Untracked: code/movingfilesto_ppl.R
Untracked: code/pearson_extract_func.R
Untracked: code/pearson_tox_extract.R
Untracked: code/plot1C.fun.R
Untracked: code/spearman_extract_func.R
Untracked: code/venndiagramcolor_control.R
Untracked: cormotif_p.post.list_4.csv
Untracked: figS1024h.pdf
Untracked: individual-legenddark2.png
Untracked: installed_old.rda
Untracked: motif_ER.txt
Untracked: motif_LR.txt
Untracked: motif_NR.txt
Untracked: motif_TI.txt
Untracked: output/DNR_DEGlist.csv
Untracked: output/DNRvenn.RDS
Untracked: output/DOX_DEGlist.csv
Untracked: output/DOXvenn.RDS
Untracked: output/EPI_DEGlist.csv
Untracked: output/EPIvenn.RDS
Untracked: output/Figures/
Untracked: output/MTX_DEGlist.csv
Untracked: output/MTXvenn.RDS
Untracked: output/TRZ_DEGlist.csv
Untracked: output/TableS8.csv
Untracked: output/Volcanoplot_10
Untracked: output/Volcanoplot_10.RDS
Untracked: output/allfinal_sup10.RDS
Untracked: output/endocytosisgenes.csv
Untracked: output/gene_corr_fig9.RDS
Untracked: output/legend_b.RDS
Untracked: output/motif_ERrep.RDS
Untracked: output/motif_LRrep.RDS
Untracked: output/motif_NRrep.RDS
Untracked: output/motif_TI_rep.RDS
Untracked: output/output-old/
Untracked: output/rank24genes.csv
Untracked: output/rank3genes.csv
Untracked: output/reneem@ls6.tacc.utexas.edu
Untracked: output/sequencinginformationforsupp.csv
Untracked: output/sequencinginformationforsupp.prn
Untracked: output/sigVDA24.txt
Untracked: output/sigVDA3.txt
Untracked: output/sigVDX24.txt
Untracked: output/sigVDX3.txt
Untracked: output/sigVEP24.txt
Untracked: output/sigVEP3.txt
Untracked: output/sigVMT24.txt
Untracked: output/sigVMT3.txt
Untracked: output/sigVTR24.txt
Untracked: output/sigVTR3.txt
Untracked: output/supplementary_motif_list_GO.RDS
Untracked: output/toptablebydrug.RDS
Untracked: output/tvl24hour.txt
Untracked: output/x_counts.RDS
Untracked: reneebasecode.R
Unstaged changes:
Modified: analysis/Figure6.Rmd
Modified: analysis/Figure7.Rmd
Modified: analysis/Figure8.Rmd
Modified: analysis/GOI_plots.Rmd
Modified: analysis/Knowles2019.Rmd
Modified: analysis/LDH_analysis.Rmd
Modified: analysis/Supplementary_figures.Rmd
Modified: analysis/run_all_analysis.Rmd
Modified: analysis/variance_scrip.Rmd
Modified: output/daplot.RDS
Modified: output/dxplot.RDS
Modified: output/epplot.RDS
Modified: output/mtplot.RDS
Modified: output/plan2plot.png
Modified: output/trplot.RDS
Modified: output/veplot.RDS
Note that any generated files, e.g. HTML, png, CSS, etc., are not included in this status report because it is ok for generated content to have uncommitted changes.
These are the previous versions of the repository in which changes were
made to the R Markdown (analysis/Figure9.Rmd) and HTML
(docs/Figure9.html) files. If you’ve configured a remote
Git repository (see ?wflow_git_remote), click on the
hyperlinks in the table below to view the files as they were in that
past version.
| File | Version | Author | Date | Message |
|---|---|---|---|---|
| Rmd | 3989a79 | reneeisnowhere | 2023-09-28 | updates to figures and links |
| html | 67c37be | reneeisnowhere | 2023-09-28 | Build site. |
| Rmd | a51139d | reneeisnowhere | 2023-09-28 | updates to figures and links |
| html | c6faf91 | reneeisnowhere | 2023-07-28 | Build site. |
| Rmd | 62286c3 | reneeisnowhere | 2023-07-28 | Updateing figure code |
| html | c40aced | reneeisnowhere | 2023-07-26 | Build site. |
| Rmd | 58c7965 | reneeisnowhere | 2023-07-26 | updating figures |
| html | 78ab76b | reneeisnowhere | 2023-07-18 | Build site. |
| html | ae0d1cb | reneeisnowhere | 2023-07-17 | Build site. |
| Rmd | f018c8e | reneeisnowhere | 2023-07-17 | addingin cpm plots too! |
| html | 13d05d5 | reneeisnowhere | 2023-07-17 | Build site. |
| Rmd | 9d7a515 | reneeisnowhere | 2023-07-17 | adding in new plots change in color |
| html | b485511 | reneeisnowhere | 2023-07-14 | Build site. |
| Rmd | 66450a6 | reneeisnowhere | 2023-07-14 | updated tox heatmaps |
| html | ed18a48 | reneeisnowhere | 2023-07-07 | Build site. |
| Rmd | 63d054a | reneeisnowhere | 2023-07-07 | Various changes to graphs. pending Monday-renames |
| html | 0e3d22d | reneeisnowhere | 2023-07-06 | Build site. |
| Rmd | 6a6c9af | reneeisnowhere | 2023-07-06 | adding fig 5 and changing fig9 heatmap |
| Rmd | a95c83e | reneeisnowhere | 2023-07-06 | update code |
| html | 0bbe4ce | reneeisnowhere | 2023-07-06 | Build site. |
| Rmd | d7fa0ae | reneeisnowhere | 2023-07-06 | adding heatmaps and plots |
| Rmd | 26c55b3 | reneeisnowhere | 2023-07-06 | adding heatmaps and plots |
library(edgeR)
library(tidyverse)
library(ggsignif)
library(RColorBrewer)
library(cowplot)
library(ggpubr)
library(scales)
library(sjmisc)
library(kableExtra)
library(broom)
library(ComplexHeatmap)toplistall <- readRDS("data/toplistall.RDS")
siglist <- readRDS("data/siglist_final.RDS")
list2env(siglist, envir = .GlobalEnv)<environment: R_GlobalEnv>cpmcounts <- readRDS("data/cpmcount.RDS")
backGL <- read.csv("data/backGL.txt", row.names =1)
drug_palc <- c("#8B006D","#DF707E","#F1B72B", "#3386DD","#707031","#41B333")
drug_pal_fact <- c("#8B006D" ,"#DF707E", "#F1B72B" ,"#3386DD", "#707031","#41B333")
col_fun1 = circlize::colorRamp2(c(-1, 3), c("white", "purple"))
col_funFC= circlize::colorRamp2(c(-2,0, 2), c("darkgreen","white", "darkorange2"))
col_funTOX = circlize::colorRamp2(c(-1,0, 1), c("darkviolet", "white","firebrick4"))pearson_extract <- function(corr_df,ENTREZID) {
ld50_plot <- corr_df %>%
dplyr::filter(entrezgene_id == ENTREZID) %>%
ggplot(., aes(x=LD50, y=counts))+
geom_point(aes(col=indv))+
geom_smooth(method="lm")+
facet_wrap(hgnc_symbol~Drug, scales="free")+
theme_classic()+
stat_cor(method="pearson",
aes(label = paste(..r.label.., ..p.label.., sep = "~`,`~")),
color = "red",
label.x.npc = 0,
label.y.npc=1,
size = 3)
tnni_plot <- corr_df %>%
dplyr::filter(entrezgene_id == ENTREZID) %>%
ggplot(., aes(x=rtnni, y=counts))+
geom_point(aes(col=indv))+
geom_smooth(method="lm")+
facet_wrap(hgnc_symbol~Drug, scales="free")+
theme_classic()+
stat_cor(method="pearson",
aes(label = paste(..r.label.., ..p.label.., sep = "~`,`~")),
color = "red",
label.x.npc = 0,
label.y.npc=1,
size = 3)
ldh_plot <- corr_df %>%
dplyr::filter(entrezgene_id == ENTREZID) %>%
ggplot(., aes(x=rldh, y=counts))+
geom_point(aes(col=indv))+
geom_smooth(method="lm")+
facet_wrap(hgnc_symbol~Drug, scales="free")+
theme_classic()+
stat_cor(method="pearson",
aes(label = paste(..r.label.., ..p.label.., sep = "~`,`~")),
color = "red",
label.x.npc = 0,
label.y.npc=1,
size = 3)
##ggbuild to get model:
ld50_build <- ggplot_build(ld50_plot)
ld50_data <- data.frame('rho_LD50'= c(ld50_build$data[[3]]$r,NA,NA),
'sig_LD50'=c(ld50_build$data[[3]]$p.value,NA,NA),
'rowname'=c("DOX","EPI","DNR","MTX", "TRZ", "VEH"))
tnni_build <- ggplot_build(tnni_plot)
tnni_data <- data.frame('rho_tnni'= c(tnni_build$data[[3]]$r),
'sig_tnni'=c(tnni_build$data[[3]]$p.value),
'rowname'=c("DOX","EPI","DNR","MTX", "TRZ", "VEH"))
ldh_build <- ggplot_build(ldh_plot)
ldh_data <- data.frame('rho_ldh'= c(ldh_build$data[[3]]$r),
'sig_ldh'=c(ldh_build$data[[3]]$p.value),
'rowname'=c("DOX","EPI","DNR","MTX", "TRZ", "VEH"))
results <- cbind(ldh_data[,c(3,1:2)],tnni_data[,1:2],ld50_data[,1:2])
return(results)
}
cpm_boxplot24h <-function(cpmcounts, GOI,brewer_palette, fill_colors, ylab) {
##GOI needs to be ENTREZID
df <- cpmcounts
df_plot <- df %>%
dplyr::filter(rownames(.)==GOI) %>%
pivot_longer(everything(),
names_to = "treatment",
values_to = "counts") %>%
separate(treatment, c("drug","indv","time")) %>%
mutate(time = case_match(time,"24h"~"24 hours", "3h"~"3 hours")) %>%
mutate(indv=factor(indv, levels = c(1,2,3,4,5,6))) %>%
mutate(drug =case_match(drug, "Da"~"DNR",
"Do"~"DOX",
"Ep"~"EPI",
"Mi"~"MTX",
"Tr"~"TRZ",
"Ve"~"VEH", .default = drug)) %>%
mutate(drug=factor(drug, levels = c('DOX','EPI','DNR','MTX','TRZ','VEH'))) %>%
dplyr::filter(time=="24 hours")
plot <- ggplot2::ggplot(df_plot, aes(x=drug, y=counts))+
geom_boxplot(position="identity",aes(fill=drug))+
geom_point(aes(col=indv, size=2, alpha=0.5))+
guides(alpha= "none", size= "none")+
scale_color_brewer(palette = brewer_palette, guide = "none")+
scale_fill_manual(values=fill_colors)+
# facet_wrap("time", nrow=1, ncol=2)+
theme_bw()+
ylab(ylab)+
xlab("")+
ggtitle("24 hours")+
theme(strip.background = element_rect(fill = "white",linetype=1, linewidth = 0.5),
plot.title = element_text(size=12,hjust = 0.5,face="bold"),
axis.title = element_text(size = 10, color = "black"),
axis.ticks = element_line(linewidth = 1.0),
panel.background = element_rect(colour = "black", size=1),
axis.text.x = element_blank(),
strip.text.x = element_text(margin = margin(2,0,2,0, "pt"),face = "bold"))
print(plot)
}
pearson_cardiotox <- function(corr_df,ENTREZID) {
full_plot <- corr_df %>%
dplyr::filter(entrezgene_id == ENTREZID) %>%
ggplot(., aes(x=tox_score, y=counts))+
geom_point(aes(col=indv))+
geom_smooth(method="lm")+
facet_wrap(hgnc_symbol~Drug, scales="free")+
theme_classic()+
stat_cor(method="pearson",
aes(label = paste(..r.label.., ..p.label.., sep = "~`,`~")),
color = "red",
label.x.npc = 0,
label.y.npc=1,
size = 3)
##ggbuild to get model:
tox_build <- ggplot_build(full_plot)
tox_data <- data.frame('rowname'=c("DOX","EPI","DNR","MTX", "TRZ", "VEH"),
'tox_val'= c(tox_build$data[[3]]$r,NA,NA),
'sig_tox'=c(tox_build$data[[3]]$p.value,NA,NA)
)
return(tox_data)
}Figure 9: Genes in AC toxicity-associated loci respond to TOP2i
A. GWAS and TWAS associated genes
GWAS_goi <- read.csv("output/GWAS_goi.csv",row.names = 1)
##get the abs FC of all GOI
GWASabsFCsig <-
toplistall %>%
mutate(drug=factor(id, levels = c('DOX','EPI','DNR','MTX','TRZ','VEH'))) %>%
filter(ENTREZID %in% GWAS_goi$entrezgene_id) %>%
filter(time =="24_hours") %>%
dplyr::select(ENTREZID , id,logFC, adj.P.Val, SYMBOL) %>%
pivot_wider(id_cols=id,
names_from = SYMBOL,
values_from =adj.P.Val)
gwas_sig_mat <- GWASabsFCsig %>%
column_to_rownames(var="id") %>%
as.matrix()
GWASabsFC <- toplistall %>%
# filter(id !="TRZ") %>%
filter(time=="24_hours") %>%
mutate(logFC= logFC*(-1)) %>%
filter(ENTREZID %in% GWAS_goi$entrezgene_id) %>%
dplyr::select(SYMBOL ,time, id, logFC) %>%
pivot_wider(id_cols=id,
names_from = SYMBOL,
values_from = logFC) %>%
column_to_rownames(var="id") %>%
as.matrix()
study_anno <- data.frame(Study=c("GWAS","GWAS","TWAS","TWAS","GWAS","GWAS","GWAS","TWAS"),motif=c(rep("LR",7),"NR"))
rownames(study_anno) <- colnames(GWASabsFC)
ht <- HeatmapAnnotation(df = study_anno,
col = list(Study=c("GWAS"="darkorange","TWAS"= "blueviolet"),motif = c("LR"="#7CAE00","NR"="#C77CFF"), just = "left"))
Heatmap(GWASabsFC, name = "Fold change\nvalues",
cluster_rows = FALSE,
cluster_columns = FALSE,
row_names_side = "left",
col = col_funFC,
row_order = c('DOX','EPI','DNR', 'MTX','TRZ'),
column_title = "Fold change values of GWAS and TWAS genes",
column_title_side = "top",
column_title_gp = gpar(fontsize = 16, fontface = "bold"),
column_order= c('RARG',
'TNS2',
'ZNF740',
'SLC28A3',
'RMI1',
'EEF1B2',
'FRS2',
'HDDC2'),
bottom_annotation = ht,
column_names_rot = 0,
column_names_gp = gpar(fontsize = 12,fontface="italic"),
column_names_centered =TRUE,
cell_fun = function(j, i, x, y, width, height, fill) {
if(gwas_sig_mat[i, j] <0.05)
grid.text("*", x, y, gp = gpar(fontsize = 20))
})
B. Lactate dehydrogenase release
RNAnormlist <- read.csv("output/TNNI_LDH_RNAnormlist.txt")
level_order2 <- c('75','87','77','79','78','71')
RNAnormlist <- RNAnormlist %>%
mutate(indv= factor(indv,levels= level_order2))
RNAnormlist %>%
mutate(Drug = factor(Drug, levels = c( "DOX",
"EPI",
"DNR",
"MTX",
"TRZ",
"VEH"))) %>%
ggplot(., aes(x=Drug, y=rldh))+
geom_boxplot(position = "identity", fill = drug_pal_fact)+
geom_point(aes(col=indv, size =3,alpha=0.5))+
geom_signif(comparisons =list(c("VEH","DOX"),
c("VEH","EPI"),
c("VEH","DNR"),
c("VEH","MTX"),
c("VEH","TRZ")),
test="t.test",
map_signif_level=TRUE,
textsize =4,
step_increase = 0.1)+
theme_classic()+
guides(size = "none",alpha="none")+
scale_color_brewer(palette = "Dark2", name = "Individual")+
xlab("")+
ylab("Relative LDH activity ")+
ggtitle("Lactate dehydrogenase release at 24 hours")+
theme_classic()+
theme(strip.background = element_rect(fill = "transparent")) +
theme(plot.title = element_text(size = rel(1.5), hjust = 0.5),
legend.position = "none",
axis.title = element_text(size = 15, color = "black"),
axis.ticks = element_line(linewidth = 1.5),
axis.line = element_line(linewidth = 1.5),
axis.text = element_text(size = 12, color = "black", angle = 0),
strip.text.x = element_text(size = 15, color = "black", face = "bold"))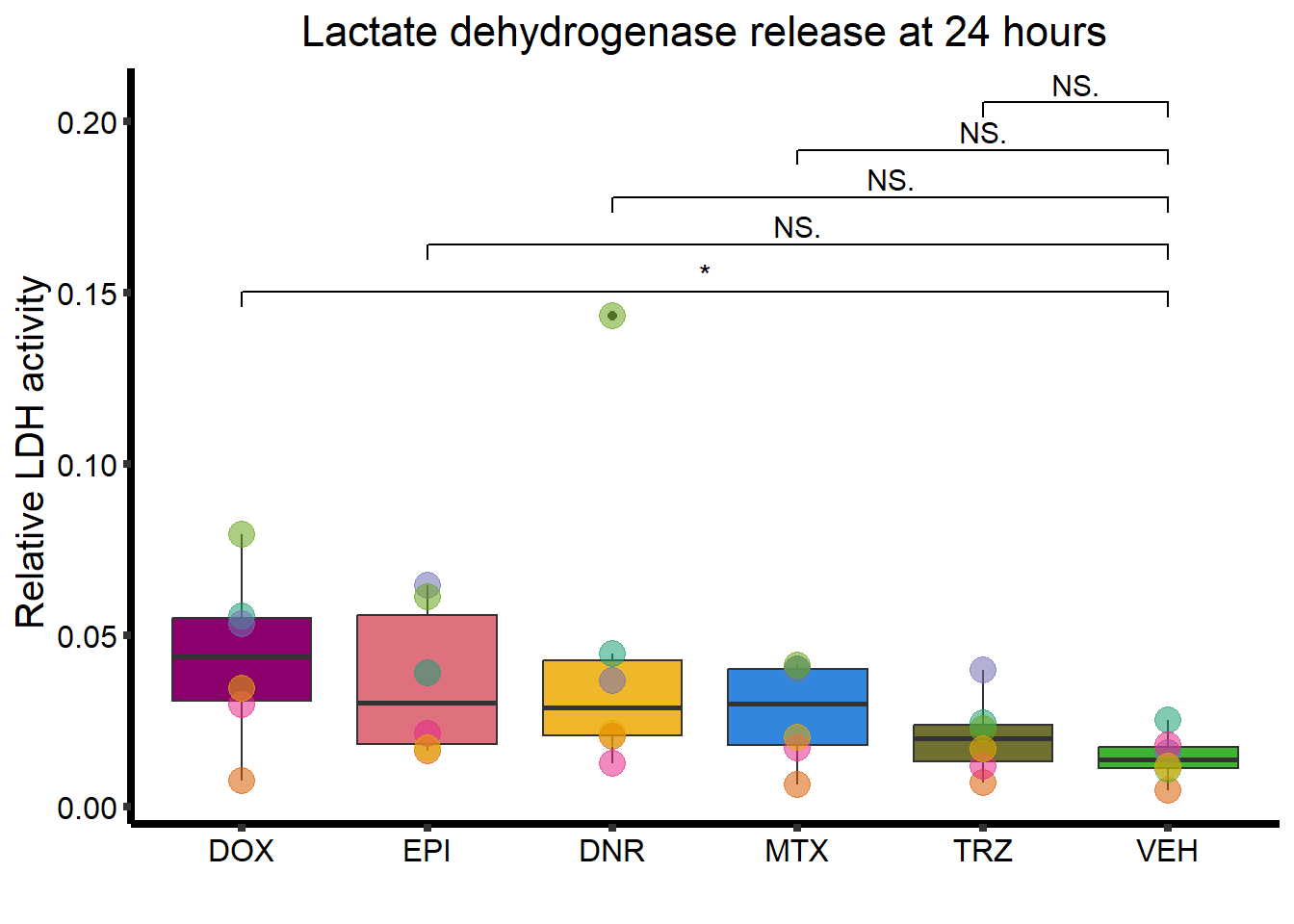
| Version | Author | Date |
|---|---|---|
| 67c37be | reneeisnowhere | 2023-09-28 |
C. Troponin I release
RNAnormlist %>%
mutate(Drug = factor(Drug, levels = c( "DOX",
"EPI",
"DNR",
"MTX",
"TRZ",
"VEH"))) %>%
ggplot(., aes(x=Drug, y=rtnni))+
geom_boxplot(position = "identity", fill = drug_pal_fact)+
geom_point(aes(col=indv, size =3,alpha=0.5))+
geom_signif(comparisons =list(c("VEH","DOX"),
c("VEH","EPI"),
c("VEH","DNR"),
c("VEH","MTX"),
c("VEH","TRZ")),
test="t.test",
map_signif_level=TRUE,
textsize =4,
step_increase = 0.1)+
theme_classic()+
guides(size = "none",alpha="none")+
scale_color_brewer(palette = "Dark2", name = "Individual")+
xlab("")+
ylab("Relative Troponin I levels ")+
ggtitle("Troponin I release at 24 hours")+
theme_classic()+
theme(strip.background = element_rect(fill = "transparent")) +
theme(plot.title = element_text(size = rel(1.5), hjust = 0.5),
legend.position = "none",
axis.title = element_text(size = 15, color = "black"),
axis.ticks = element_line(linewidth = 1.5),
axis.line = element_line(linewidth = 1.5),
axis.text = element_text(size = 12, color = "black", angle = 0),
strip.text.x = element_text(size = 15, color = "black", face = "bold"))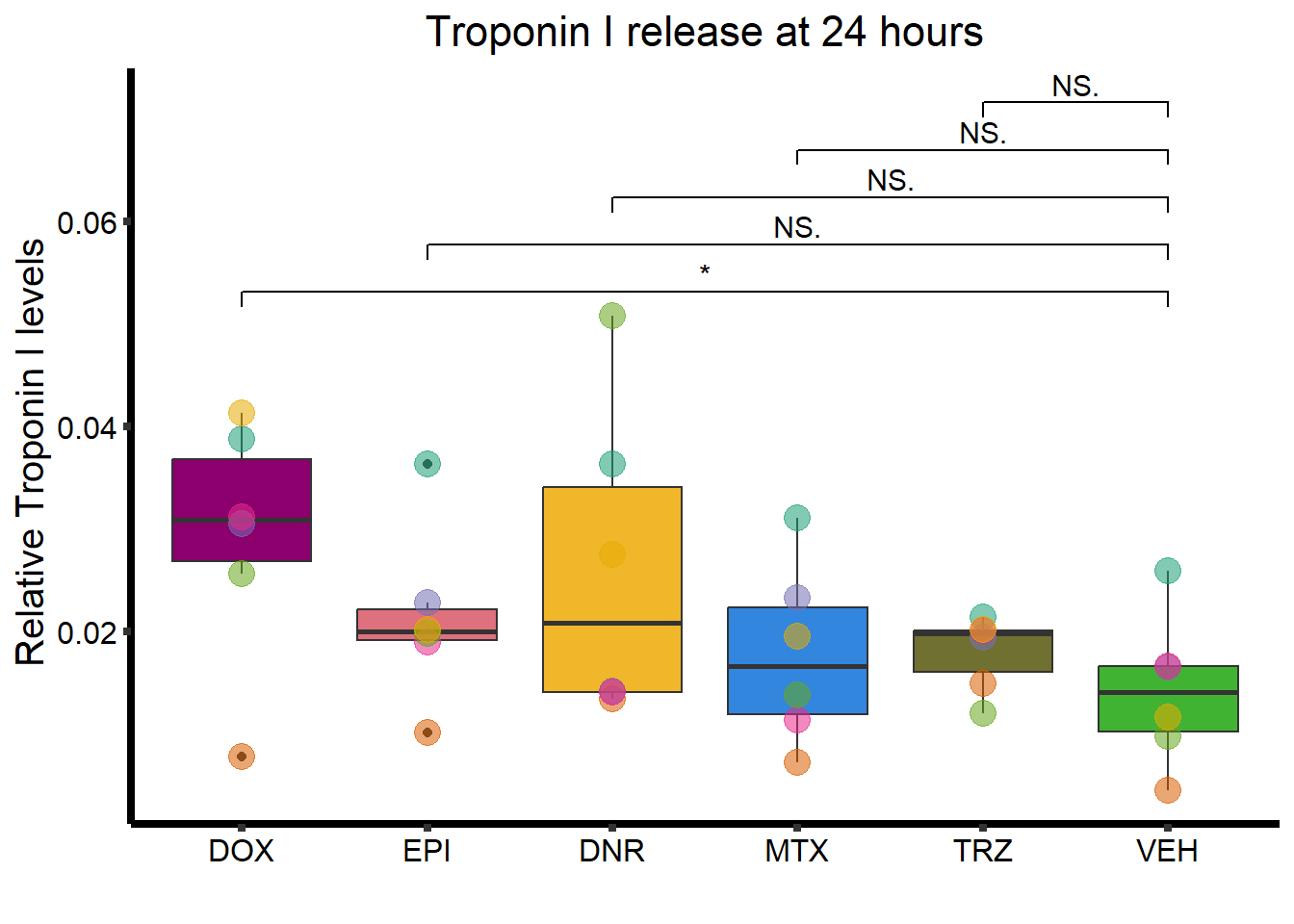
| Version | Author | Date |
|---|---|---|
| 67c37be | reneeisnowhere | 2023-09-28 |
For more Troponin I and LDH release analysis, check this link out
Cardiotoxicity Score code
gene_corr_fig9 <- readRDS("output/gene_corr_fig9.RDS")
toxlist <- data.frame(ENTREZID = c(5916, 23371, 283337, 64078, 80010))
toxtest_2pt <- gene_corr_fig9 %>%
rowwise() %>%
# mutate_all(~replace(., is.na(.), 0)) %>%
mutate(tox_score = mean(c(rldh, rtnni), na.rm = TRUE)) %>%
dplyr::select(entrezgene_id, hgnc_symbol, Drug, indv, time, counts, tox_score) %>%
filter(entrezgene_id %in% toxlist$ENTREZID)
toxdata2pt <- list()
for (hay in 1:5) {
data <- toxtest_2pt %>%
dplyr::filter(entrezgene_id == toxlist$ENTREZID[hay])
dataname <- unique(data$hgnc_symbol)
p <- ggplot(data, aes(x = tox_score, y = counts)) +
geom_point(aes(col = indv)) +
geom_smooth(method = "lm") +
facet_wrap(hgnc_symbol ~ Drug, scales = "free") +
theme_classic() +
scale_color_brewer(
palette = "Dark2",
name = "Individual",
label = c("1", "2", "3", "4", "5", "6")
) +
ggpubr::stat_cor(
method = "pearson",
aes(label = paste(..r.label.., ..p.label.., sep = "~`,`~")),
color = "red",
label.x.npc = 0,
label.y.npc = 1,
size = 3
)
tox_build <- ggplot_build(p)
# plot(p)
toxdata2pt[[dataname]] <- list(
'tox_val' = c(tox_build$data[[3]]$r),
'sig_tox' = c(tox_build$data[[3]]$p.value)
)
}extraction code for heatmap below gene expression boxes ### D. SNP-related gene expression and cardiotoxicity score
The extraction code for the horizontal heatmap below gene expression boxplots in the paper is located here.
RARG
cpm_boxplot24h(cpmcounts,GOI='5916',"Dark2",drug_pal_fact,
ylab=(expression(atop(" ",italic("RARG")~log[2]~"cpm "))))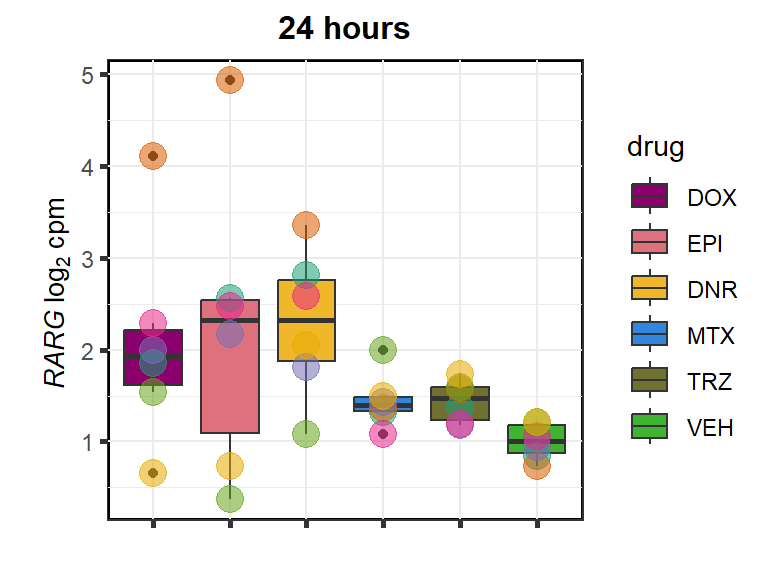
toxdata2ptr <- map_df(toxdata2pt, ~as.data.frame(.x), .id="gene")
RARG_sig_mat2ptr <- toxdata2ptr %>%
dplyr::filter(gene=="RARG") %>%
dplyr::select(sig_tox) %>%
t() %>%
matrix()
RARG_mat2ptr <- toxdata2ptr%>%
dplyr::filter(gene=="RARG") %>%
dplyr::select(tox_val) %>%
t() %>%
matrix()
Heatmap(RARG_mat2ptr, name = " RARG 2pt Cardiotox score",
cluster_rows = FALSE,
cluster_columns = FALSE,
row_names_side = "left",
column_title_side = "top",
column_title_gp = gpar(fontsize = 16, fontface = "bold"),
column_names_rot = 0,
col= col_funTOX,
row_labels = c("DOX","EPI","DNR","MTX","TRZ","VEH"),
column_names_gp = gpar(fontsize = 12,fontface="italic"),
column_names_centered = TRUE,
cell_fun = function(j, i, x, y, width, height, fill) {
if(RARG_sig_mat2ptr[i, j] <0.05)
grid.text("*", x, y, gp = gpar(fontsize = 20))
})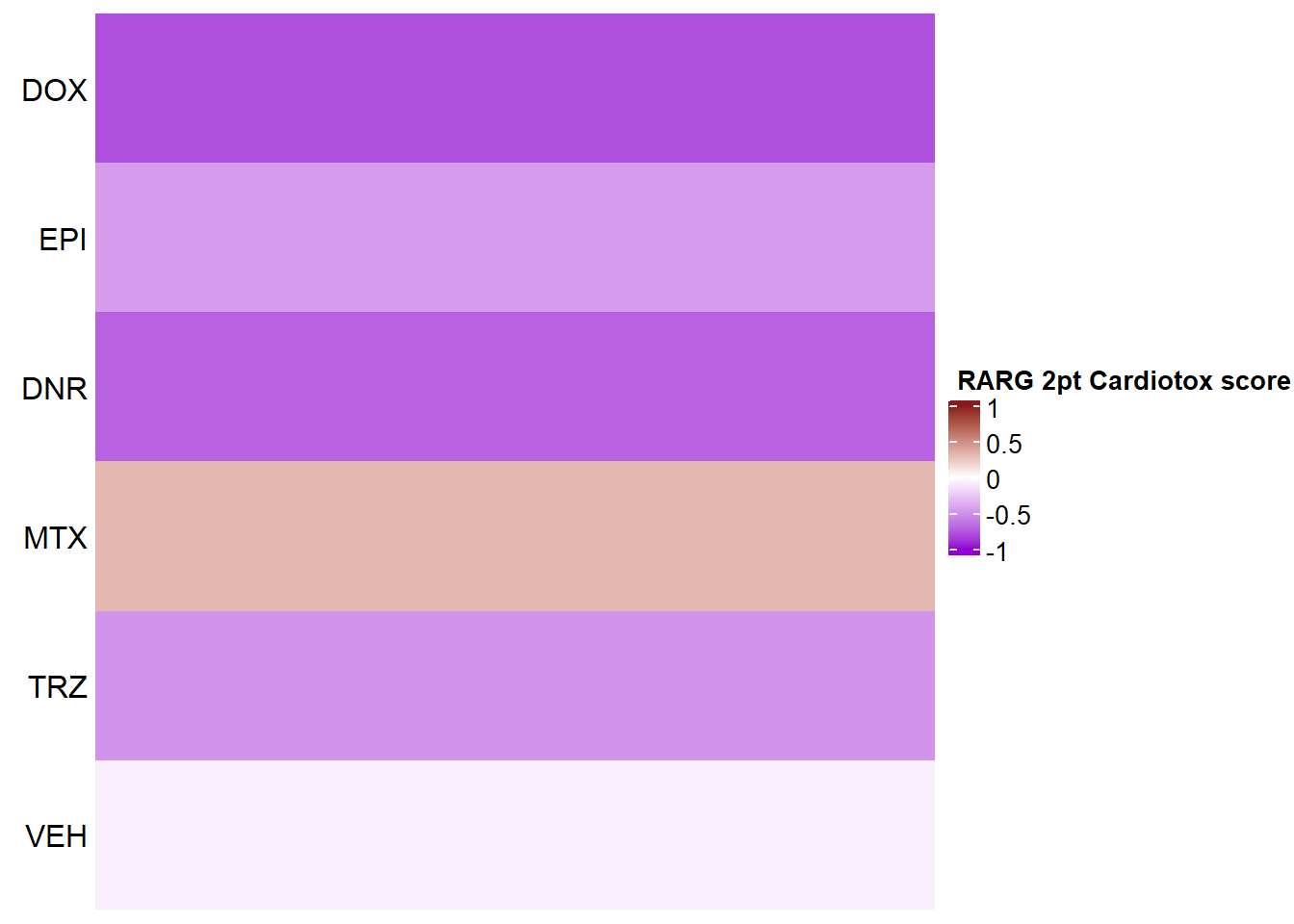
TNS2
cpm_boxplot24h(cpmcounts,GOI='23371',"Dark2",drug_pal_fact,
ylab=(expression(atop(" ",italic("TNS2")~log[2]~"cpm "))))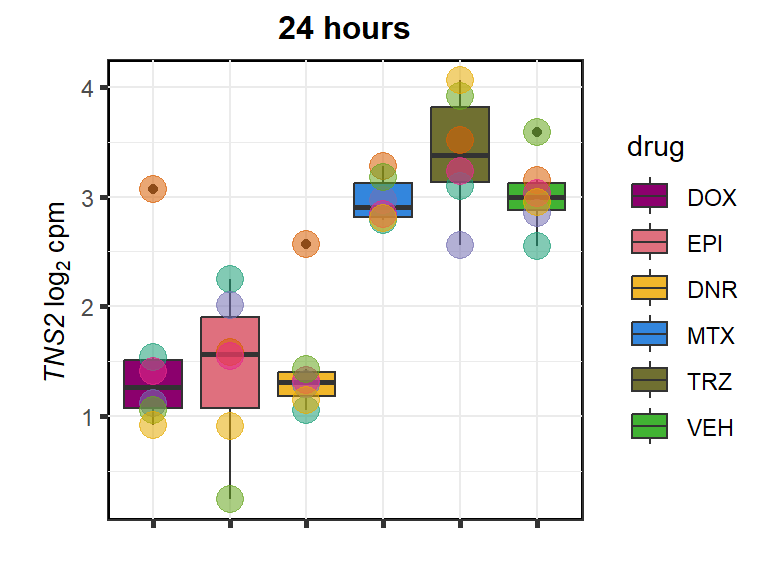
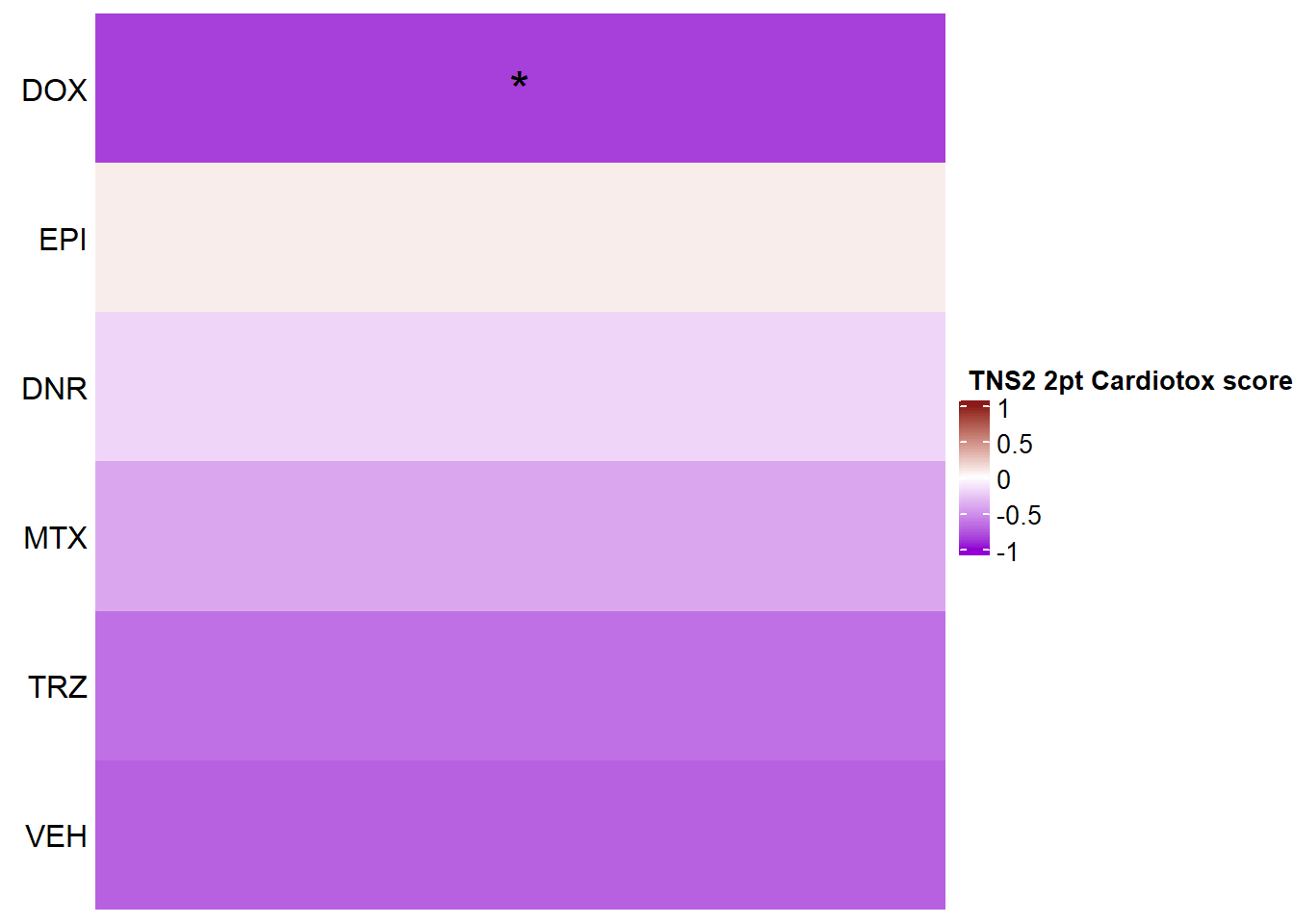
TNS2_sig_mat2ptr <- toxdata2ptr %>%
dplyr::filter(gene=="TNS2") %>%
dplyr::select(sig_tox) %>%
t() %>%
matrix()
TNS2_mat2ptr <- toxdata2ptr%>%
dplyr::filter(gene=="TNS2") %>%
dplyr::select(tox_val) %>%
t() %>%
matrix()
Heatmap(TNS2_mat2ptr, name = " TNS2 2pt Cardiotox score",
cluster_rows = FALSE,
cluster_columns = FALSE,
row_names_side = "left",
column_title_side = "top",
column_title_gp = gpar(fontsize = 16, fontface = "bold"),
column_names_rot = 0,
col= col_funTOX,
row_labels = c("DOX","EPI","DNR","MTX","TRZ","VEH"),
column_names_gp = gpar(fontsize = 12,fontface="italic"),
column_names_centered = TRUE,
cell_fun = function(j, i, x, y, width, height, fill) {
if(TNS2_sig_mat2ptr[i, j] <0.05)
grid.text("*", x, y, gp = gpar(fontsize = 20))
})
ZNF740
cpm_boxplot24h(cpmcounts,GOI='283337',"Dark2",drug_pal_fact,
ylab=(expression(atop(" ",italic("ZNF740")~log[2]~"cpm "))))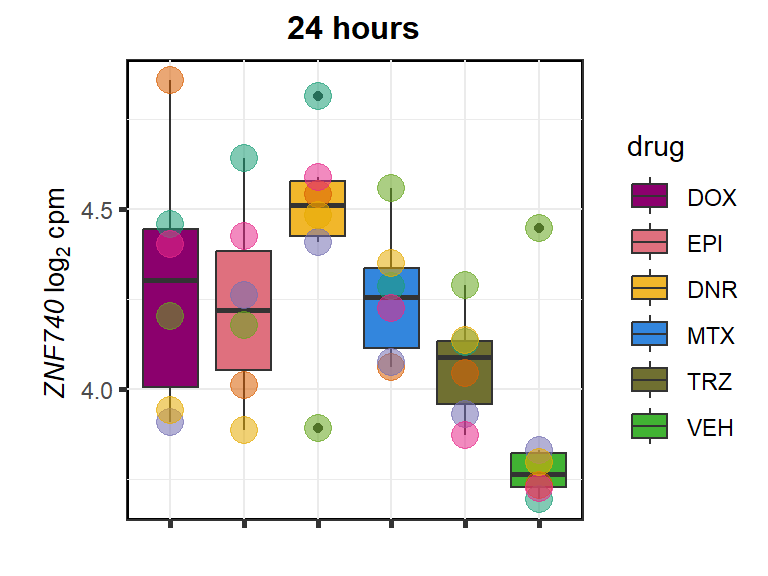
ZNF740_sig_mat2ptr <- toxdata2ptr %>%
dplyr::filter(gene=="ZNF740") %>%
dplyr::select(sig_tox) %>%
t() %>%
matrix()
ZNF740_mat2ptr <- toxdata2ptr%>%
dplyr::filter(gene=="ZNF740") %>%
dplyr::select(tox_val) %>%
t() %>%
matrix()
Heatmap(ZNF740_mat2ptr, name = " ZNF740 2pt Cardiotox score",
cluster_rows = FALSE,
cluster_columns = FALSE,
row_names_side = "left",
column_title_side = "top",
column_title_gp = gpar(fontsize = 16, fontface = "bold"),
column_names_rot = 0,
col= col_funTOX,
row_labels = c("DOX","EPI","DNR","MTX","TRZ","VEH"),
column_names_gp = gpar(fontsize = 12,fontface="italic"),
column_names_centered = TRUE,
cell_fun = function(j, i, x, y, width, height, fill) {
if(ZNF740_sig_mat2ptr[i, j] <0.05)
grid.text("*", x, y, gp = gpar(fontsize = 20))
})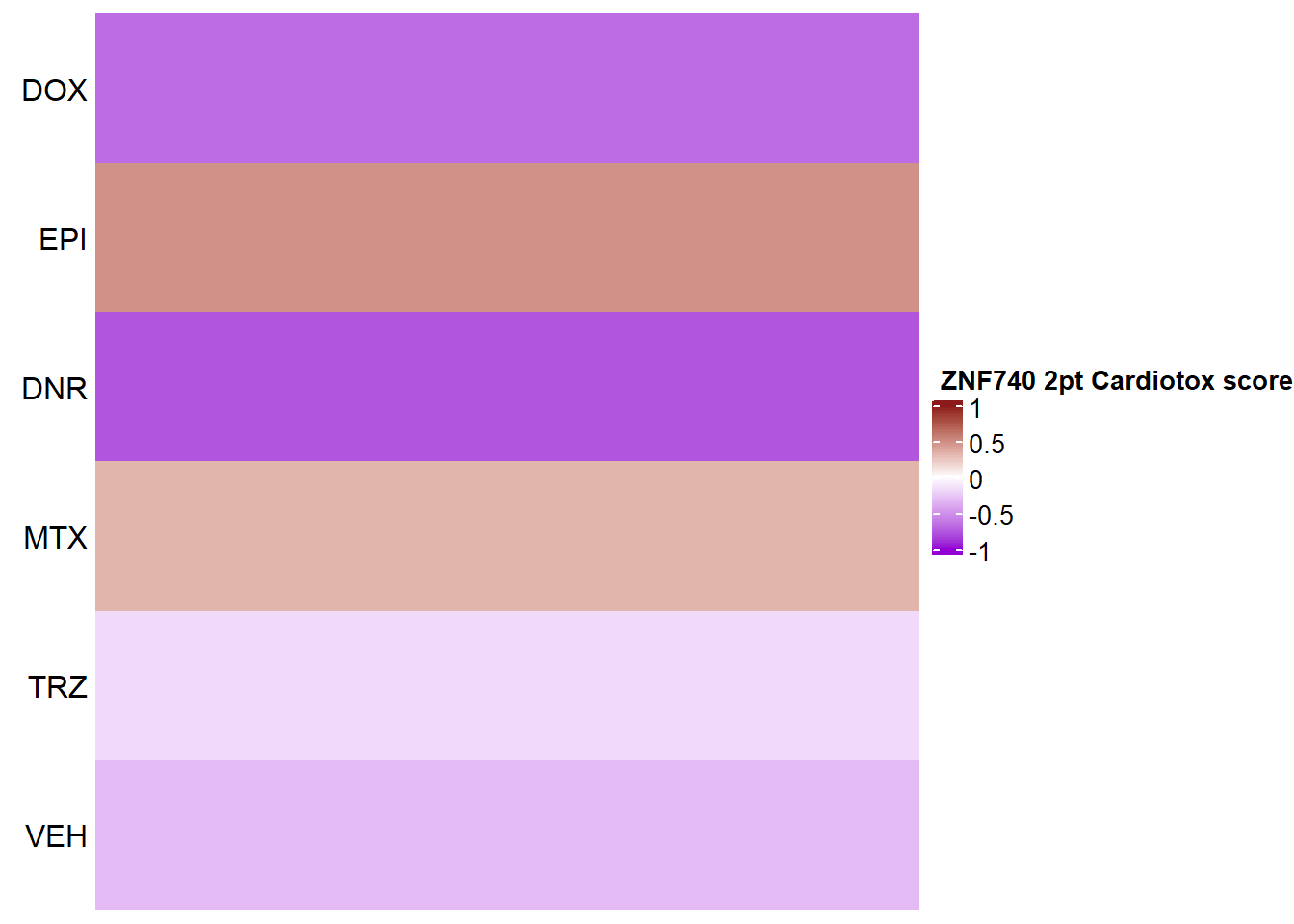
RMI1
cpm_boxplot24h(cpmcounts,GOI='80010',"Dark2",drug_pal_fact,
ylab=(expression(atop(" ",italic("RMI1")~log[2]~"cpm "))))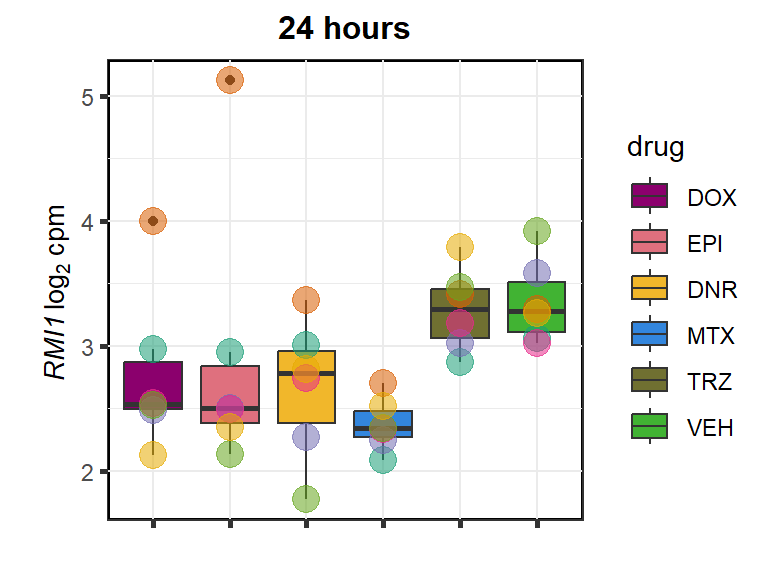
toxdata2ptr <- map_df(toxdata2pt, ~as.data.frame(.x), .id="gene")
RMI1_sig_mat2ptr <- toxdata2ptr %>%
dplyr::filter(gene=="RMI1") %>%
dplyr::select(sig_tox) %>%
t() %>%
matrix()
RMI1_mat2ptr <- toxdata2ptr%>%
dplyr::filter(gene=="RMI1") %>%
dplyr::select(tox_val) %>%
t() %>%
matrix()
Heatmap(RMI1_mat2ptr, name = " RMI1 2pt Cardiotox score",
cluster_rows = FALSE,
cluster_columns = FALSE,
row_names_side = "left",
column_title_side = "top",
column_title_gp = gpar(fontsize = 16, fontface = "bold"),
column_names_rot = 0,
col= col_funTOX,
row_labels = c("DOX","EPI","DNR","MTX","TRZ","VEH"),
column_names_gp = gpar(fontsize = 12,fontface="italic"),
column_names_centered = TRUE,
cell_fun = function(j, i, x, y, width, height, fill) {
if(RMI1_sig_mat2ptr[i, j] <0.05)
grid.text("*", x, y, gp = gpar(fontsize = 20))
})
| Version | Author | Date |
|---|---|---|
| 13d05d5 | reneeisnowhere | 2023-07-17 |
SLC28A3
cpm_boxplot24h(cpmcounts,GOI='64078',"Dark2",drug_pal_fact,
ylab=(expression(atop(" ",italic("SLC28A3")~log[2]~"cpm "))))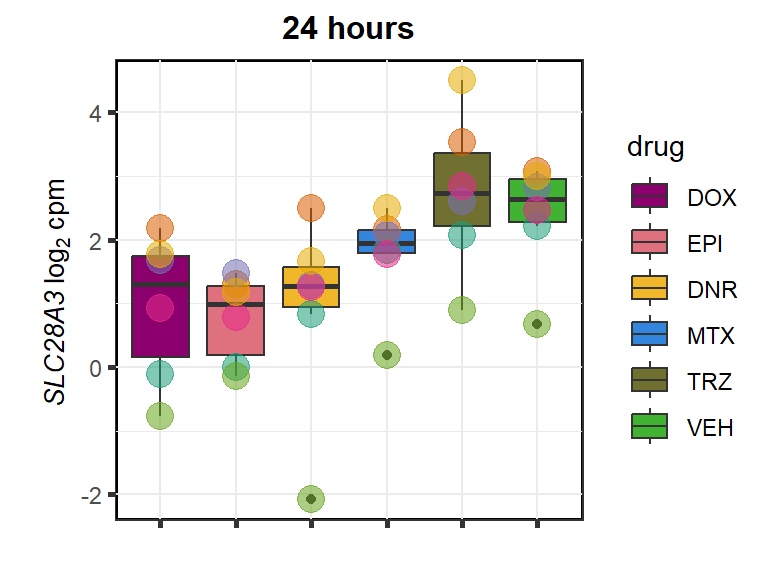
toxdata2ptr <- map_df(toxdata2pt, ~as.data.frame(.x), .id="gene")
SLC28A3_sig_mat2ptr <- toxdata2ptr %>%
dplyr::filter(gene=="SLC28A3") %>%
dplyr::select(sig_tox) %>%
t() %>%
matrix()
SLC28A3_mat2ptr <- toxdata2ptr%>%
dplyr::filter(gene=="SLC28A3") %>%
dplyr::select(tox_val) %>%
t() %>%
matrix()
Heatmap(SLC28A3_mat2ptr, name = " SLC28A3 2pt Cardiotox score",
cluster_rows = FALSE,
cluster_columns = FALSE,
row_names_side = "left",
column_title_side = "top",
column_title_gp = gpar(fontsize = 16, fontface = "bold"),
column_names_rot = 0,
col= col_funTOX,
row_labels = c("DOX","EPI","DNR","MTX","TRZ","VEH"),
column_names_gp = gpar(fontsize = 12,fontface="italic"),
column_names_centered = TRUE,
cell_fun = function(j, i, x, y, width, height, fill) {
if(SLC28A3_sig_mat2ptr[i, j] <0.05)
grid.text("*", x, y, gp = gpar(fontsize = 20))
})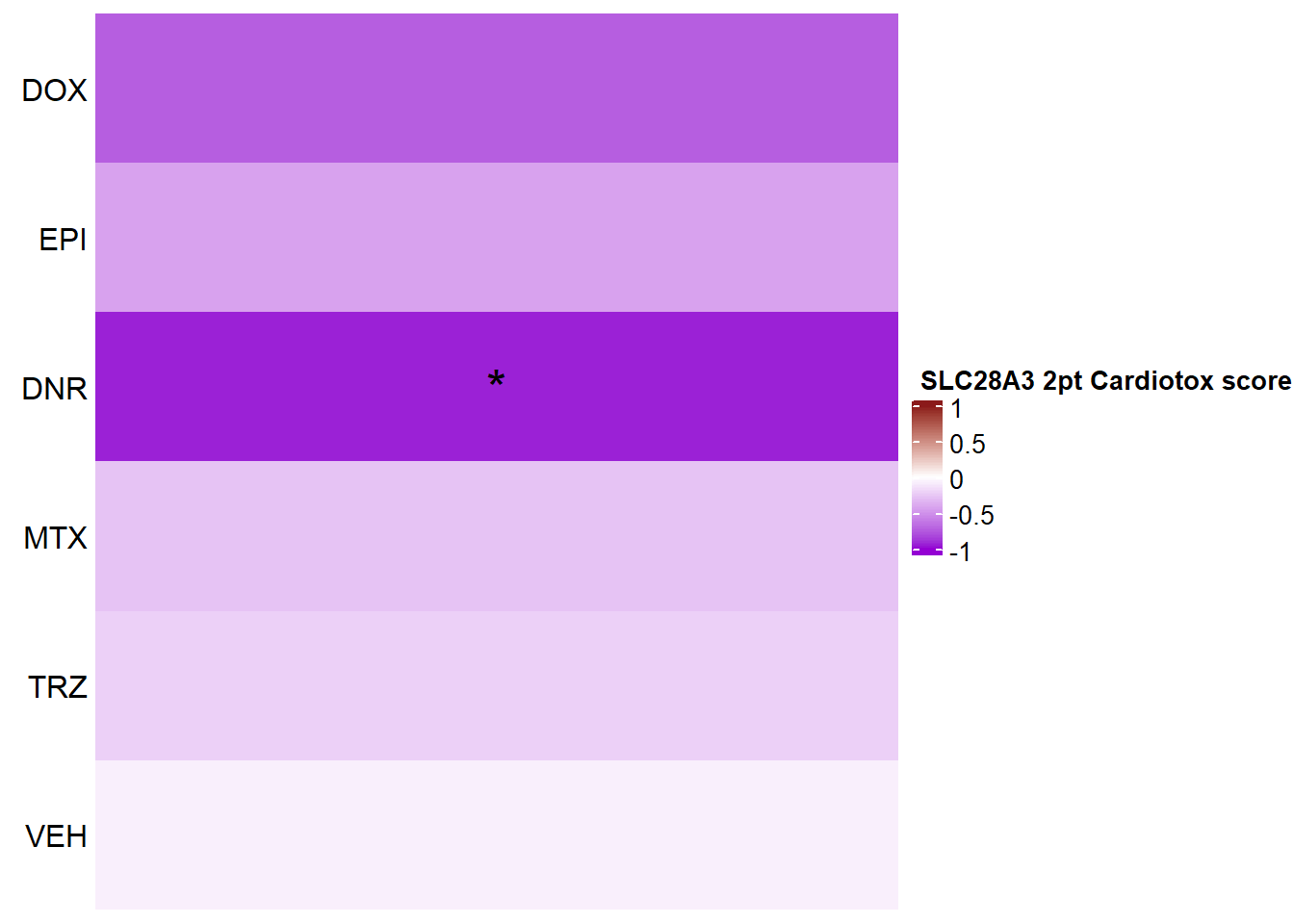
| Version | Author | Date |
|---|---|---|
| 13d05d5 | reneeisnowhere | 2023-07-17 |
sessionInfo()R version 4.3.1 (2023-06-16 ucrt)
Platform: x86_64-w64-mingw32/x64 (64-bit)
Running under: Windows 10 x64 (build 19045)
Matrix products: default
locale:
[1] LC_COLLATE=English_United States.utf8
[2] LC_CTYPE=English_United States.utf8
[3] LC_MONETARY=English_United States.utf8
[4] LC_NUMERIC=C
[5] LC_TIME=English_United States.utf8
time zone: America/Chicago
tzcode source: internal
attached base packages:
[1] grid stats graphics grDevices utils datasets methods
[8] base
other attached packages:
[1] ComplexHeatmap_2.16.0 broom_1.0.5 kableExtra_1.3.4
[4] sjmisc_2.8.9 scales_1.2.1 ggpubr_0.6.0
[7] cowplot_1.1.1 RColorBrewer_1.1-3 ggsignif_0.6.4
[10] lubridate_1.9.2 forcats_1.0.0 stringr_1.5.0
[13] dplyr_1.1.3 purrr_1.0.2 readr_2.1.4
[16] tidyr_1.3.0 tibble_3.2.1 ggplot2_3.4.3
[19] tidyverse_2.0.0 edgeR_3.42.4 limma_3.56.2
[22] workflowr_1.7.1
loaded via a namespace (and not attached):
[1] rlang_1.1.1 magrittr_2.0.3 clue_0.3-64
[4] GetoptLong_1.0.5 git2r_0.32.0 matrixStats_1.0.0
[7] compiler_4.3.1 mgcv_1.9-0 getPass_0.2-2
[10] png_0.1-8 systemfonts_1.0.4 callr_3.7.3
[13] vctrs_0.6.3 rvest_1.0.3 pkgconfig_2.0.3
[16] shape_1.4.6 crayon_1.5.2 fastmap_1.1.1
[19] backports_1.4.1 magick_2.7.5 labeling_0.4.3
[22] utf8_1.2.3 promises_1.2.1 rmarkdown_2.24
[25] tzdb_0.4.0 ps_1.7.5 xfun_0.40
[28] cachem_1.0.8 jsonlite_1.8.7 later_1.3.1
[31] parallel_4.3.1 cluster_2.1.4 R6_2.5.1
[34] bslib_0.5.1 stringi_1.7.12 car_3.1-2
[37] jquerylib_0.1.4 Rcpp_1.0.11 iterators_1.0.14
[40] knitr_1.44 IRanges_2.34.1 Matrix_1.6-1
[43] splines_4.3.1 httpuv_1.6.11 timechange_0.2.0
[46] tidyselect_1.2.0 rstudioapi_0.15.0 abind_1.4-5
[49] yaml_2.3.7 doParallel_1.0.17 codetools_0.2-19
[52] sjlabelled_1.2.0 processx_3.8.2 lattice_0.21-8
[55] withr_2.5.0 evaluate_0.21 xml2_1.3.5
[58] circlize_0.4.15 pillar_1.9.0 carData_3.0-5
[61] whisker_0.4.1 foreach_1.5.2 stats4_4.3.1
[64] insight_0.19.5 generics_0.1.3 rprojroot_2.0.3
[67] hms_1.1.3 S4Vectors_0.38.1 munsell_0.5.0
[70] glue_1.6.2 tools_4.3.1 locfit_1.5-9.8
[73] webshot_0.5.5 fs_1.6.3 colorspace_2.1-0
[76] nlme_3.1-163 cli_3.6.1 fansi_1.0.4
[79] viridisLite_0.4.2 svglite_2.1.1 gtable_0.3.4
[82] rstatix_0.7.2 sass_0.4.7 digest_0.6.33
[85] BiocGenerics_0.46.0 farver_2.1.1 rjson_0.2.21
[88] htmltools_0.5.6 lifecycle_1.0.3 httr_1.4.7
[91] GlobalOptions_0.1.2