Enhancer_enrichment
Renee Matthews
2025-05-07
Last updated: 2025-06-17
Checks: 7 0
Knit directory: ATAC_learning/
This reproducible R Markdown analysis was created with workflowr (version 1.7.1). The Checks tab describes the reproducibility checks that were applied when the results were created. The Past versions tab lists the development history.
Great! Since the R Markdown file has been committed to the Git repository, you know the exact version of the code that produced these results.
Great job! The global environment was empty. Objects defined in the global environment can affect the analysis in your R Markdown file in unknown ways. For reproduciblity it’s best to always run the code in an empty environment.
The command set.seed(20231016) was run prior to running
the code in the R Markdown file. Setting a seed ensures that any results
that rely on randomness, e.g. subsampling or permutations, are
reproducible.
Great job! Recording the operating system, R version, and package versions is critical for reproducibility.
Nice! There were no cached chunks for this analysis, so you can be confident that you successfully produced the results during this run.
Great job! Using relative paths to the files within your workflowr project makes it easier to run your code on other machines.
Great! You are using Git for version control. Tracking code development and connecting the code version to the results is critical for reproducibility.
The results in this page were generated with repository version 5e2ac5c. See the Past versions tab to see a history of the changes made to the R Markdown and HTML files.
Note that you need to be careful to ensure that all relevant files for
the analysis have been committed to Git prior to generating the results
(you can use wflow_publish or
wflow_git_commit). workflowr only checks the R Markdown
file, but you know if there are other scripts or data files that it
depends on. Below is the status of the Git repository when the results
were generated:
Ignored files:
Ignored: .RData
Ignored: .Rhistory
Ignored: .Rproj.user/
Ignored: analysis/H3K27ac_integration_noM.Rmd
Ignored: data/ACresp_SNP_table.csv
Ignored: data/ARR_SNP_table.csv
Ignored: data/All_merged_peaks.tsv
Ignored: data/CAD_gwas_dataframe.RDS
Ignored: data/CTX_SNP_table.csv
Ignored: data/Collapsed_expressed_NG_peak_table.csv
Ignored: data/DEG_toplist_sep_n45.RDS
Ignored: data/FRiP_first_run.txt
Ignored: data/Final_four_data/
Ignored: data/Frip_1_reads.csv
Ignored: data/Frip_2_reads.csv
Ignored: data/Frip_3_reads.csv
Ignored: data/Frip_4_reads.csv
Ignored: data/Frip_5_reads.csv
Ignored: data/Frip_6_reads.csv
Ignored: data/GO_KEGG_analysis/
Ignored: data/HF_SNP_table.csv
Ignored: data/Ind1_75DA24h_dedup_peaks.csv
Ignored: data/Ind1_TSS_peaks.RDS
Ignored: data/Ind1_firstfragment_files.txt
Ignored: data/Ind1_fragment_files.txt
Ignored: data/Ind1_peaks_list.RDS
Ignored: data/Ind1_summary.txt
Ignored: data/Ind2_TSS_peaks.RDS
Ignored: data/Ind2_fragment_files.txt
Ignored: data/Ind2_peaks_list.RDS
Ignored: data/Ind2_summary.txt
Ignored: data/Ind3_TSS_peaks.RDS
Ignored: data/Ind3_fragment_files.txt
Ignored: data/Ind3_peaks_list.RDS
Ignored: data/Ind3_summary.txt
Ignored: data/Ind4_79B24h_dedup_peaks.csv
Ignored: data/Ind4_TSS_peaks.RDS
Ignored: data/Ind4_V24h_fraglength.txt
Ignored: data/Ind4_fragment_files.txt
Ignored: data/Ind4_fragment_filesN.txt
Ignored: data/Ind4_peaks_list.RDS
Ignored: data/Ind4_summary.txt
Ignored: data/Ind5_TSS_peaks.RDS
Ignored: data/Ind5_fragment_files.txt
Ignored: data/Ind5_fragment_filesN.txt
Ignored: data/Ind5_peaks_list.RDS
Ignored: data/Ind5_summary.txt
Ignored: data/Ind6_TSS_peaks.RDS
Ignored: data/Ind6_fragment_files.txt
Ignored: data/Ind6_peaks_list.RDS
Ignored: data/Ind6_summary.txt
Ignored: data/Knowles_4.RDS
Ignored: data/Knowles_5.RDS
Ignored: data/Knowles_6.RDS
Ignored: data/LiSiLTDNRe_TE_df.RDS
Ignored: data/MI_gwas.RDS
Ignored: data/SNP_GWAS_PEAK_MRC_id
Ignored: data/SNP_GWAS_PEAK_MRC_id.csv
Ignored: data/SNP_gene_cat_list.tsv
Ignored: data/SNP_supp_schneider.RDS
Ignored: data/TE_info/
Ignored: data/TFmapnames.RDS
Ignored: data/all_TSSE_scores.RDS
Ignored: data/all_four_filtered_counts.txt
Ignored: data/aln_run1_results.txt
Ignored: data/anno_ind1_DA24h.RDS
Ignored: data/anno_ind4_V24h.RDS
Ignored: data/annotated_gwas_SNPS.csv
Ignored: data/background_n45_he_peaks.RDS
Ignored: data/cardiac_muscle_FRIP.csv
Ignored: data/cardiomyocyte_FRIP.csv
Ignored: data/col_ng_peak.csv
Ignored: data/cormotif_full_4_run.RDS
Ignored: data/cormotif_full_4_run_he.RDS
Ignored: data/cormotif_full_6_run.RDS
Ignored: data/cormotif_full_6_run_he.RDS
Ignored: data/cormotif_probability_45_list.csv
Ignored: data/cormotif_probability_45_list_he.csv
Ignored: data/cormotif_probability_all_6_list.csv
Ignored: data/cormotif_probability_all_6_list_he.csv
Ignored: data/datasave.RDS
Ignored: data/embryo_heart_FRIP.csv
Ignored: data/enhancer_list_ENCFF126UHK.bed
Ignored: data/enhancerdata/
Ignored: data/filt_Peaks_efit2.RDS
Ignored: data/filt_Peaks_efit2_bl.RDS
Ignored: data/filt_Peaks_efit2_n45.RDS
Ignored: data/first_Peaksummarycounts.csv
Ignored: data/first_run_frag_counts.txt
Ignored: data/full_bedfiles/
Ignored: data/gene_ref.csv
Ignored: data/gwas_1_dataframe.RDS
Ignored: data/gwas_2_dataframe.RDS
Ignored: data/gwas_3_dataframe.RDS
Ignored: data/gwas_4_dataframe.RDS
Ignored: data/gwas_5_dataframe.RDS
Ignored: data/high_conf_peak_counts.csv
Ignored: data/high_conf_peak_counts.txt
Ignored: data/high_conf_peaks_bl_counts.txt
Ignored: data/high_conf_peaks_counts.txt
Ignored: data/hits_files/
Ignored: data/hyper_files/
Ignored: data/hypo_files/
Ignored: data/ind1_DA24hpeaks.RDS
Ignored: data/ind1_TSSE.RDS
Ignored: data/ind2_TSSE.RDS
Ignored: data/ind3_TSSE.RDS
Ignored: data/ind4_TSSE.RDS
Ignored: data/ind4_V24hpeaks.RDS
Ignored: data/ind5_TSSE.RDS
Ignored: data/ind6_TSSE.RDS
Ignored: data/initial_complete_stats_run1.txt
Ignored: data/left_ventricle_FRIP.csv
Ignored: data/median_24_lfc.RDS
Ignored: data/median_3_lfc.RDS
Ignored: data/mergedPeads.gff
Ignored: data/mergedPeaks.gff
Ignored: data/motif_list_full
Ignored: data/motif_list_n45
Ignored: data/motif_list_n45.RDS
Ignored: data/multiqc_fastqc_run1.txt
Ignored: data/multiqc_fastqc_run2.txt
Ignored: data/multiqc_genestat_run1.txt
Ignored: data/multiqc_genestat_run2.txt
Ignored: data/my_hc_filt_counts.RDS
Ignored: data/my_hc_filt_counts_n45.RDS
Ignored: data/n45_bedfiles/
Ignored: data/n45_files
Ignored: data/other_papers/
Ignored: data/peakAnnoList_1.RDS
Ignored: data/peakAnnoList_2.RDS
Ignored: data/peakAnnoList_24_full.RDS
Ignored: data/peakAnnoList_24_n45.RDS
Ignored: data/peakAnnoList_3.RDS
Ignored: data/peakAnnoList_3_full.RDS
Ignored: data/peakAnnoList_3_n45.RDS
Ignored: data/peakAnnoList_4.RDS
Ignored: data/peakAnnoList_5.RDS
Ignored: data/peakAnnoList_6.RDS
Ignored: data/peakAnnoList_Eight.RDS
Ignored: data/peakAnnoList_full_motif.RDS
Ignored: data/peakAnnoList_n45_motif.RDS
Ignored: data/siglist_full.RDS
Ignored: data/siglist_n45.RDS
Ignored: data/summarized_peaks_dataframe.txt
Ignored: data/summary_peakIDandReHeat.csv
Ignored: data/test.list.RDS
Ignored: data/testnames.txt
Ignored: data/toplist_6.RDS
Ignored: data/toplist_full.RDS
Ignored: data/toplist_full_DAR_6.RDS
Ignored: data/toplist_n45.RDS
Ignored: data/trimmed_seq_length.csv
Ignored: data/unclassified_full_set_peaks.RDS
Ignored: data/unclassified_n45_set_peaks.RDS
Ignored: data/xstreme/
Untracked files:
Untracked: RNA_seq_integration.Rmd
Untracked: Rplot.pdf
Untracked: Sig_meta
Untracked: analysis/.gitignore
Untracked: analysis/AC_shared_analysis.Rmd
Untracked: analysis/Cormotif_analysis_testing diff.Rmd
Untracked: analysis/Diagnosis-tmm.Rmd
Untracked: analysis/Enhancer_enrichment_ALL_DAR.Rmd
Untracked: analysis/Expressed_RNA_associations.Rmd
Untracked: analysis/GO_analysis_DAR.Rmd
Untracked: analysis/Jaspar_motif_DAR.Rmd
Untracked: analysis/LFC_corr.Rmd
Untracked: analysis/SNP_TAD_peaks.Rmd
Untracked: analysis/SVA.Rmd
Untracked: analysis/Tan2020.Rmd
Untracked: analysis/Top2B_analysis.Rmd
Untracked: analysis/making_master_peaks_list.Rmd
Untracked: analysis/my_hc_filt_counts.csv
Untracked: code/Concatenations_for_export.R
Untracked: code/IGV_snapshot_code.R
Untracked: code/LongDARlist.R
Untracked: code/just_for_Fun.R
Untracked: my_plot.pdf
Untracked: my_plot.png
Untracked: output/cormotif_probability_45_list.csv
Untracked: output/cormotif_probability_all_6_list.csv
Untracked: setup.RData
Unstaged changes:
Modified: ATAC_learning.Rproj
Modified: analysis/AF_HF_SNPs.Rmd
Modified: analysis/Cardiotox_SNPs.Rmd
Modified: analysis/Cormotif_analysis.Rmd
Modified: analysis/DEG_analysis.Rmd
Modified: analysis/H3K27ac_initial_QC.Rmd
Modified: analysis/Jaspar_motif.Rmd
Modified: analysis/Jaspar_motif_ff.Rmd
Modified: analysis/TE_analysis_norm.Rmd
Modified: analysis/final_four_analysis.Rmd
Note that any generated files, e.g. HTML, png, CSS, etc., are not included in this status report because it is ok for generated content to have uncommitted changes.
These are the previous versions of the repository in which changes were
made to the R Markdown
(analysis/Enhancer_enrichment_DOX_DAR.Rmd) and HTML
(docs/Enhancer_enrichment_DOX_DAR.html) files. If you’ve
configured a remote Git repository (see ?wflow_git_remote),
click on the hyperlinks in the table below to view the files as they
were in that past version.
| File | Version | Author | Date | Message |
|---|---|---|---|---|
| html | eeaa3e6 | reneeisnowhere | 2025-06-09 | Build site. |
| Rmd | 7a30fff | reneeisnowhere | 2025-06-09 | updateing enrichment test |
| html | e105fcf | reneeisnowhere | 2025-06-06 | Build site. |
| Rmd | bcd95ae | reneeisnowhere | 2025-06-06 | adding DAR analysis |
| html | 2554021 | reneeisnowhere | 2025-06-06 | Build site. |
| Rmd | 31c168e | reneeisnowhere | 2025-06-06 | adding DAR analysis |
library(tidyverse)
library(kableExtra)
library(broom)
library(RColorBrewer)
library(ChIPseeker)
library("TxDb.Hsapiens.UCSC.hg38.knownGene")
library("org.Hs.eg.db")
library(rtracklayer)
library(edgeR)
library(ggfortify)
library(limma)
library(readr)
library(BiocGenerics)
library(gridExtra)
library(VennDiagram)
library(scales)
library(BiocParallel)
library(ggpubr)
library(devtools)
library(biomaRt)
library(eulerr)
library(smplot2)
library(genomation)
library(ggsignif)
library(plyranges)
library(ggrepel)
library(epitools)
library(circlize)Collapsed_peaks <- read_delim("data/Final_four_data/collapsed_new_peaks.txt",
delim = "\t",
escape_double = FALSE,
trim_ws = TRUE)
toptable_results <- readRDS("data/Final_four_data/re_analysis/Toptable_results.RDS")
all_regions <- toptable_results$DOX_24$genes
Collapsed_peaks <- read_delim("data/Final_four_data/collapsed_new_peaks.txt",
delim = "\t",
escape_double = FALSE,
trim_ws = TRUE)
final_peaks <- Collapsed_peaks %>%
dplyr::filter(chr != "chrY") %>%
dplyr::filter(Peakid %in% all_regions) %>%
GRanges()
all_results <- toptable_results %>%
imap(~ .x %>% tibble::rownames_to_column(var = "rowname") %>%
mutate(source = .y)) %>%
bind_rows()
my_dar_data <- all_results %>%
dplyr::filter(source=="DOX_3"|source=="DOX_24") %>%
dplyr::select(source,genes,logFC,adj.P.Val) %>%
pivot_wider(.,id_cols=genes,names_from = source, values_from = c(logFC, adj.P.Val))Enhancers and Response clusters
First: obtained a list of cis Regulatory Elements from Encode Screen [(https://screen.encodeproject.org/#)]
cREs_HLV_46F <- genomation::readBed("data/enhancerdata/ENCFF867HAD_ENCFF152PBB_ENCFF352YYH_ENCFF252IVK.7group.bed")
Whole_peaks <- join_overlap_intersect(final_peaks, cREs_HLV_46F)
Whole_peaks %>%
as.data.frame() %>%
group_by(blockCount) %>%
tally() %>%
kable(., caption="Breakdown of peaks overlapping cREs") %>%
kable_paper("striped", full_width = TRUE) %>%
kable_styling(full_width = FALSE, font_size = 14)| blockCount | n |
|---|---|
| CTCF-only,CTCF-bound | 7161 |
| DNase-H3K4me3 | 1239 |
| DNase-H3K4me3,CTCF-bound | 819 |
| DNase-only | 5502 |
| Low-DNase | 174148 |
| PLS | 13986 |
| PLS,CTCF-bound | 3703 |
| dELS | 11809 |
| dELS,CTCF-bound | 2542 |
| pELS | 16069 |
| pELS,CTCF-bound | 3572 |
keep_cRE_names <- c("CTCF-only,CTCF-bound" ,"PLS,CTCF-bound","PLS","dELS,CTCF-bound", "pELS","pELS,CTCF-bound","dELS")
is_cRE <- Whole_peaks %>%
as.data.frame() %>%
dplyr::filter(blockCount %in% keep_cRE_names) %>%
distinct(Peakid,blockCount)
is_CTCF <- Whole_peaks %>%
as.data.frame() %>%
dplyr::filter(blockCount == "CTCF-only,CTCF-bound") %>%
distinct(Peakid,blockCount)
is_dELS <- Whole_peaks %>%
as.data.frame() %>%
dplyr::filter(blockCount == "dELS,CTCF-bound"|blockCount == "dELS") %>%
distinct(Peakid,blockCount)
is_pELS <- Whole_peaks %>%
as.data.frame() %>%
dplyr::filter(blockCount == "pELS,CTCF-bound"|blockCount == "pELS") %>%
distinct(Peakid,blockCount)
is_PLS <- Whole_peaks %>%
as.data.frame() %>%
dplyr::filter(blockCount == "PLS,CTCF-bound"|blockCount == "PLS") %>%
distinct(Peakid,blockCount)
CRE_summary <-final_peaks %>%
as.data.frame() %>%
mutate(cRE_status=if_else(Peakid %in% is_cRE$Peakid,"cRE_peak","not_cRE_peak")) %>%
mutate(CTCF_status=if_else(Peakid %in% is_CTCF$Peakid,"CTCF_peak","not_CTCF_peak")) %>%
mutate(dELS_status=if_else(Peakid %in% is_dELS$Peakid,"dELS_peak","not_dELS_peak")) %>%
mutate(pELS_status=if_else(Peakid %in% is_pELS$Peakid,"pELS_peak","not_pELS_peak")) %>%
mutate(PLS_status=if_else(Peakid %in% is_PLS$Peakid,"PLS_peak","not_PLS_peak")) %>%
dplyr::select(Peakid:PLS_status) %>%
left_join(.,my_dar_data,by=c("Peakid"="genes")) %>%
mutate(sig_3=if_else(adj.P.Val_DOX_3<0.05,"sig","not_sig"),
sig_24=if_else(adj.P.Val_DOX_24<0.05,"sig","not_sig")) %>%
mutate(sig_3=factor(sig_3,levels=c("sig","not_sig")),
sig_24=factor(sig_24,levels=c("sig","not_sig"))) %>%
mutate(sig_up_3 = case_when(
adj.P.Val_DOX_3 < 0.05 & logFC_DOX_3 > 0 ~ "sig_up",
TRUE ~ "not_sig_up"
)) %>%
mutate(sig_down_3 = case_when(
adj.P.Val_DOX_3 < 0.05 & logFC_DOX_3 < 0 ~ "sig_down",
TRUE ~ "not_sig_down"
)) %>%
mutate(sig_up_24 = case_when(
adj.P.Val_DOX_24 < 0.05 & logFC_DOX_24 > 0 ~ "sig_up",
TRUE ~ "not_sig_up"
)) %>%
mutate(sig_down_24 = case_when(
adj.P.Val_DOX_24 < 0.05 & logFC_DOX_24 < 0 ~ "sig_down",
TRUE ~ "not_sig_down"
)) %>%
mutate(sig_up_3=factor(sig_up_3,levels=c("sig_up","not_sig_up")),
sig_down_3=factor(sig_down_3,levels=c("sig_down","not_sig_down")),
sig_up_24=factor(sig_up_24,levels=c("sig_up","not_sig_up")),
sig_down_24=factor(sig_down_24,levels=c("sig_down","not_sig_down"))) status_columns <- c("cRE_status", "CTCF_status","dELS_status", "pELS_status","PLS_status")
DOX_3_status_matrices <- map(status_columns, function(status_col) {
# Extract prefix (e.g., "TE", "SINE") from column name like "TE_status"
prefix <- sub("_status$", "", status_col)
expected_rows <- c(paste0(prefix,"_peak"), paste0("not_", prefix,"_peak"))
expected_cols <- c("sig", "not_sig")
# Build matrix
mat <- CRE_summary %>%
group_by(across(all_of(status_col)), sig_3) %>%
tally() %>%
pivot_wider(
names_from = sig_3,
values_from = n,
values_fill = list(n = 0)
) %>%
column_to_rownames(var = status_col) %>%
as.matrix()
# Fill missing expected rows
for (r in setdiff(expected_rows, rownames(mat))) {
mat <- rbind(mat, setNames(rep(0, length(expected_cols)), expected_cols))
rownames(mat)[nrow(mat)] <- r
}
# Fill missing expected columns
for (c in setdiff(expected_cols, colnames(mat))) {
mat <- cbind(mat, setNames(rep(0, nrow(mat)), c))
}
# Order
mat <- mat[expected_rows, expected_cols, drop = FALSE]
})
# Set names so you can easily refer to each status
names(DOX_3_status_matrices) <- status_columns
odds_ratio_results_DOX_3 <- map(DOX_3_status_matrices, function(mat) {
if (!all(dim(mat) == c(2, 2)) || any(!is.finite(mat)) || sum(mat) == 0 || any(rowSums(mat) == 0) || any(colSums(mat) == 0)) {
return(NULL)
}
result <- epitools::oddsratio(mat, method = "wald")
or <- result$measure[2, "estimate"]
lower <- result$measure[2, "lower"]
upper <- result$measure[2, "upper"]
pval_chisq <- if("chi.square" %in% colnames(result$p.value) && nrow(result$p.value) >= 2) {
result$p.value[2, "chi.square"]
} else {
NA_real_
}
list(
odds_ratio = or,
lower_ci = lower,
upper_ci = upper,
chi_sq_p = pval_chisq
)
})DOX_24_status_matrices <- map(status_columns, function(status_col) {
# Extract prefix (e.g., "TE", "SINE") from column name like "TE_status"
prefix <- sub("_status$", "", status_col)
expected_rows <- c(paste0(prefix,"_peak"), paste0("not_", prefix,"_peak"))
expected_cols <- c("sig", "not_sig")
# Build matrix
mat <- CRE_summary %>%
group_by(across(all_of(status_col)), sig_24) %>%
tally() %>%
pivot_wider(
names_from = sig_24,
values_from = n,
values_fill = list(n = 0)
) %>%
column_to_rownames(var = status_col) %>%
as.matrix()
# Fill missing expected rows
for (r in setdiff(expected_rows, rownames(mat))) {
mat <- rbind(mat, setNames(rep(0, length(expected_cols)), expected_cols))
rownames(mat)[nrow(mat)] <- r
}
# Fill missing expected columns
for (c in setdiff(expected_cols, colnames(mat))) {
mat <- cbind(mat, setNames(rep(0, nrow(mat)), c))
}
# Order
mat <- mat[expected_rows, expected_cols, drop = FALSE]
})
# Set names so you can easily refer to each status
names(DOX_24_status_matrices) <- status_columns
odds_ratio_results_DOX_24 <- map(DOX_24_status_matrices, function(mat) {
if (!all(dim(mat) == c(2, 2)) || any(!is.finite(mat)) || sum(mat) == 0 || any(rowSums(mat) == 0) || any(colSums(mat) == 0)) {
return(NULL)
}
result <- epitools::oddsratio(mat, method = "wald")
or <- result$measure[2, "estimate"]
lower <- result$measure[2, "lower"]
upper <- result$measure[2, "upper"]
pval_chisq <- if("chi.square" %in% colnames(result$p.value) && nrow(result$p.value) >= 2) {
result$p.value[2, "chi.square"]
} else {
NA_real_
}
list(
odds_ratio = or,
lower_ci = lower,
upper_ci = upper,
chi_sq_p = pval_chisq
)
})3 hour matrix
DOX_3_sigup_status_matrices <- map(status_columns, function(status_col) {
# Extract prefix (e.g., "TE", "SINE") from column name like "TE_status"
prefix <- sub("_status$", "", status_col)
expected_rows <- c(paste0(prefix,"_peak"), paste0("not_", prefix,"_peak"))
expected_cols <- c("sig_up", "not_sig_up")
# Build matrix
mat <- CRE_summary %>%
group_by(across(all_of(status_col)), sig_up_3) %>%
tally() %>%
pivot_wider(
names_from = sig_up_3,
values_from = n,
values_fill = list(n = 0)
) %>%
column_to_rownames(var = status_col) %>%
as.matrix()
# Fill missing expected rows
for (r in setdiff(expected_rows, rownames(mat))) {
mat <- rbind(mat, setNames(rep(0, length(expected_cols)), expected_cols))
rownames(mat)[nrow(mat)] <- r
}
# Fill missing expected columns
for (c in setdiff(expected_cols, colnames(mat))) {
mat <- cbind(mat, setNames(rep(0, nrow(mat)), c))
}
# Order
mat <- mat[expected_rows, expected_cols, drop = FALSE]
})
# Set names so you can easily refer to each status
names(DOX_3_sigup_status_matrices) <- status_columns
odds_ratio_results_DOX_3_sigup <- map(DOX_3_sigup_status_matrices, function(mat) {
if (!all(dim(mat) == c(2, 2)) || any(!is.finite(mat)) || sum(mat) == 0 || any(rowSums(mat) == 0) || any(colSums(mat) == 0)) {
return(NULL)
}
result <- epitools::oddsratio(mat, method = "wald")
or <- result$measure[2, "estimate"]
lower <- result$measure[2, "lower"]
upper <- result$measure[2, "upper"]
pval_chisq <- if("chi.square" %in% colnames(result$p.value) && nrow(result$p.value) >= 2) {
result$p.value[2, "chi.square"]
} else {
NA_real_
}
list(
odds_ratio = or,
lower_ci = lower,
upper_ci = upper,
chi_sq_p = pval_chisq
)
})DOX_3_sigdown_status_matrices <- map(status_columns, function(status_col) {
# Extract prefix (e.g., "TE", "SINE") from column name like "TE_status"
prefix <- sub("_status$", "", status_col)
expected_rows <- c(paste0(prefix,"_peak"), paste0("not_", prefix,"_peak"))
expected_cols <- c("sig_down", "not_sig_down")
# Build matrix
mat <- CRE_summary %>%
group_by(across(all_of(status_col)), sig_down_3) %>%
tally() %>%
pivot_wider(
names_from = sig_down_3,
values_from = n,
values_fill = list(n = 0)
) %>%
column_to_rownames(var = status_col) %>%
as.matrix()
# Fill missing expected rows
for (r in setdiff(expected_rows, rownames(mat))) {
mat <- rbind(mat, setNames(rep(0, length(expected_cols)), expected_cols))
rownames(mat)[nrow(mat)] <- r
}
# Fill missing expected columns
for (c in setdiff(expected_cols, colnames(mat))) {
mat <- cbind(mat, setNames(rep(0, nrow(mat)), c))
}
# Order
mat <- mat[expected_rows, expected_cols, drop = FALSE]
})
# Set names so you can easily refer to each status
names(DOX_3_sigdown_status_matrices) <- status_columns
odds_ratio_results_DOX_3_sigdown <- map(DOX_3_sigdown_status_matrices, function(mat) {
if (!all(dim(mat) == c(2, 2)) || any(!is.finite(mat)) || sum(mat) == 0 || any(rowSums(mat) == 0) || any(colSums(mat) == 0)) {
return(NULL)
}
result <- epitools::oddsratio(mat, method = "wald")
or <- result$measure[2, "estimate"]
lower <- result$measure[2, "lower"]
upper <- result$measure[2, "upper"]
pval_chisq <- if("chi.square" %in% colnames(result$p.value) && nrow(result$p.value) >= 2) {
result$p.value[2, "chi.square"]
} else {
NA_real_
}
list(
odds_ratio = or,
lower_ci = lower,
upper_ci = upper,
chi_sq_p = pval_chisq
)
})24 hour matrix
DOX_24_sigup_status_matrices <- map(status_columns, function(status_col) {
# Extract prefix (e.g., "TE", "SINE") from column name like "TE_status"
prefix <- sub("_status$", "", status_col)
expected_rows <- c(paste0(prefix,"_peak"), paste0("not_", prefix,"_peak"))
expected_cols <- c("sig_up", "not_sig_up")
# Build matrix
mat <- CRE_summary %>%
group_by(across(all_of(status_col)), sig_up_24) %>%
tally() %>%
pivot_wider(
names_from = sig_up_24,
values_from = n,
values_fill = list(n = 0)
) %>%
column_to_rownames(var = status_col) %>%
as.matrix()
# Fill missing expected rows
for (r in setdiff(expected_rows, rownames(mat))) {
mat <- rbind(mat, setNames(rep(0, length(expected_cols)), expected_cols))
rownames(mat)[nrow(mat)] <- r
}
# Fill missing expected columns
for (c in setdiff(expected_cols, colnames(mat))) {
mat <- cbind(mat, setNames(rep(0, nrow(mat)), c))
}
# Order
mat <- mat[expected_rows, expected_cols, drop = FALSE]
})
# Set names so you can easily refer to each status
names(DOX_24_sigup_status_matrices) <- status_columns
odds_ratio_results_DOX_24_sigup <- map(DOX_24_sigup_status_matrices, function(mat) {
if (!all(dim(mat) == c(2, 2)) || any(!is.finite(mat)) || sum(mat) == 0 || any(rowSums(mat) == 0) || any(colSums(mat) == 0)) {
return(NULL)
}
result <- epitools::oddsratio(mat, method = "wald")
or <- result$measure[2, "estimate"]
lower <- result$measure[2, "lower"]
upper <- result$measure[2, "upper"]
pval_chisq <- if("chi.square" %in% colnames(result$p.value) && nrow(result$p.value) >= 2) {
result$p.value[2, "chi.square"]
} else {
NA_real_
}
list(
odds_ratio = or,
lower_ci = lower,
upper_ci = upper,
chi_sq_p = pval_chisq
)
})DOX_24_sigdown_status_matrices <- map(status_columns, function(status_col) {
# Extract prefix (e.g., "TE", "SINE") from column name like "TE_status"
prefix <- sub("_status$", "", status_col)
expected_rows <- c(paste0(prefix,"_peak"), paste0("not_", prefix,"_peak"))
expected_cols <- c("sig_down", "not_sig_down")
# Build matrix
mat <- CRE_summary %>%
group_by(across(all_of(status_col)), sig_down_24) %>%
tally() %>%
pivot_wider(
names_from = sig_down_24,
values_from = n,
values_fill = list(n = 0)
) %>%
column_to_rownames(var = status_col) %>%
as.matrix()
# Fill missing expected rows
for (r in setdiff(expected_rows, rownames(mat))) {
mat <- rbind(mat, setNames(rep(0, length(expected_cols)), expected_cols))
rownames(mat)[nrow(mat)] <- r
}
# Fill missing expected columns
for (c in setdiff(expected_cols, colnames(mat))) {
mat <- cbind(mat, setNames(rep(0, nrow(mat)), c))
}
# Order
mat <- mat[expected_rows, expected_cols, drop = FALSE]
})
# Set names so you can easily refer to each status
names(DOX_24_sigdown_status_matrices) <- status_columns
odds_ratio_results_DOX_24_sigdown <- map(DOX_24_sigdown_status_matrices, function(mat) {
if (!all(dim(mat) == c(2, 2)) || any(!is.finite(mat)) || sum(mat) == 0 || any(rowSums(mat) == 0) || any(colSums(mat) == 0)) {
return(NULL)
}
result <- epitools::oddsratio(mat, method = "wald")
or <- result$measure[2, "estimate"]
lower <- result$measure[2, "lower"]
upper <- result$measure[2, "upper"]
pval_chisq <- if("chi.square" %in% colnames(result$p.value) && nrow(result$p.value) >= 2) {
result$p.value[2, "chi.square"]
} else {
NA_real_
}
list(
odds_ratio = or,
lower_ci = lower,
upper_ci = upper,
chi_sq_p = pval_chisq
)
})odds ratio results
col_fun_OR = colorRamp2(c(0,1,1.5,5), c("blueviolet","white","lightgreen","green3" ))
combined_df <- bind_rows(
map_dfr(odds_ratio_results_DOX_3, ~as.data.frame(.x), .id = "status") %>% mutate(source = "DOX_3hr"),
map_dfr(odds_ratio_results_DOX_24, ~as.data.frame(.x), .id = "status") %>% mutate(source = "DOX_24hr"),
map_dfr(odds_ratio_results_DOX_3_sigup, ~as.data.frame(.x), .id = "status") %>% mutate(source = "DOX_3hr_sigup"),
map_dfr(odds_ratio_results_DOX_3_sigdown, ~as.data.frame(.x), .id = "status") %>% mutate(source = "DOX_3hr_sigdown"),
map_dfr(odds_ratio_results_DOX_24_sigup, ~as.data.frame(.x), .id = "status") %>% mutate(source = "DOX_24hr_sigup"),
map_dfr(odds_ratio_results_DOX_24_sigdown, ~as.data.frame(.x), .id = "status") %>% mutate(source = "DOX_24hr_sigdown")
)
sig_mat_OR <-combined_df %>%
dplyr::select( status,source,chi_sq_p) %>%
group_by(source) %>%
mutate(rank_val=rank(chi_sq_p, ties.method = "first")) %>%
mutate(BH_correction= p.adjust(chi_sq_p,method= "BH")) %>%
pivot_wider(., id_cols = status, names_from = source, values_from = BH_correction) %>%
column_to_rownames("status") %>%
as.matrix()
combined_df status odds_ratio lower_ci upper_ci chi_sq_p source
1 cRE_status 1.8186681 1.6917152 1.9551481 1.198370e-60 DOX_3hr
2 CTCF_status 0.5596008 0.4532787 0.6908620 4.365469e-08 DOX_3hr
3 dELS_status 2.9470047 2.6903132 3.2281879 6.402191e-131 DOX_3hr
4 pELS_status 1.3748517 1.2238218 1.5445200 7.283218e-08 DOX_3hr
5 PLS_status 1.1125600 0.9865355 1.2546835 8.190022e-02 DOX_3hr
6 cRE_status 0.8144925 0.7942718 0.8352279 1.050122e-57 DOX_24hr
7 CTCF_status 0.5357704 0.5080652 0.5649863 8.539290e-121 DOX_24hr
8 dELS_status 1.5176826 1.4583578 1.5794206 1.562239e-94 DOX_24hr
9 pELS_status 0.6732629 0.6459938 0.7016831 2.677836e-79 DOX_24hr
10 PLS_status 0.5785605 0.5557696 0.6022861 4.655572e-160 DOX_24hr
11 cRE_status 1.5071547 1.3304573 1.7073192 8.467935e-11 DOX_3hr_sigup
12 CTCF_status 0.2433161 0.1435930 0.4122955 1.194909e-08 DOX_3hr_sigup
13 dELS_status 0.9207514 0.7293961 1.1623083 4.871786e-01 DOX_3hr_sigup
14 pELS_status 2.1454957 1.8218336 2.5266589 7.215422e-21 DOX_3hr_sigup
15 PLS_status 2.7856102 2.4118175 3.2173346 6.461880e-48 DOX_3hr_sigup
16 cRE_status 1.9857646 1.8181482 2.1688336 1.997431e-54 DOX_3hr_sigdown
17 CTCF_status 0.7420472 0.5895826 0.9339387 1.071810e-02 DOX_3hr_sigdown
18 dELS_status 4.2717044 3.8620543 4.7248064 9.887669e-207 DOX_3hr_sigdown
19 pELS_status 0.9761253 0.8273851 1.1516049 7.745052e-01 DOX_3hr_sigdown
20 PLS_status 0.3547971 0.2775382 0.4535629 5.495686e-18 DOX_3hr_sigdown
21 cRE_status 0.2831030 0.2715728 0.2951227 0.000000e+00 DOX_24hr_sigup
22 CTCF_status 0.1716907 0.1532935 0.1922958 7.125475e-260 DOX_24hr_sigup
23 dELS_status 0.5437895 0.5128126 0.5766377 1.076716e-94 DOX_24hr_sigup
24 pELS_status 0.2689604 0.2496058 0.2898159 5.597767e-297 DOX_24hr_sigup
25 PLS_status 0.1841673 0.1695725 0.2000182 0.000000e+00 DOX_24hr_sigup
26 cRE_status 1.8429476 1.7922702 1.8950578 0.000000e+00 DOX_24hr_sigdown
27 CTCF_status 1.1926048 1.1270257 1.2619998 9.891974e-10 DOX_24hr_sigdown
28 dELS_status 2.5678360 2.4631451 2.6769765 0.000000e+00 DOX_24hr_sigdown
29 pELS_status 1.3751395 1.3149478 1.4380865 1.563802e-44 DOX_24hr_sigdown
30 PLS_status 1.3054254 1.2504617 1.3628051 4.268412e-34 DOX_24hr_sigdowncombined_df %>%
dplyr::select(status, source, odds_ratio) %>%
mutate(status=factor(status, levels=c("cRE_status","PLS_status","pELS_status","dELS_status","CTCF_status"))) %>%
arrange(status) %>%
group_by(source) %>%
pivot_wider(., id_cols = status, names_from = source, values_from = odds_ratio) %>%
column_to_rownames("status") %>%
as.matrix() %>%
ComplexHeatmap::Heatmap(. ,col = col_fun_OR,
cluster_rows=FALSE,
cluster_columns=FALSE,
column_names_side = "top",
column_names_rot = 45,
# na_col = "black",
cell_fun = function(j, i, x, y, width, height, fill) {if (!is.na(sig_mat_OR[i, j]) && sig_mat_OR[i, j] < 0.05 && .[i, j] > 1) {
grid.text("*", x, y, gp = gpar(fontsize = 20))}})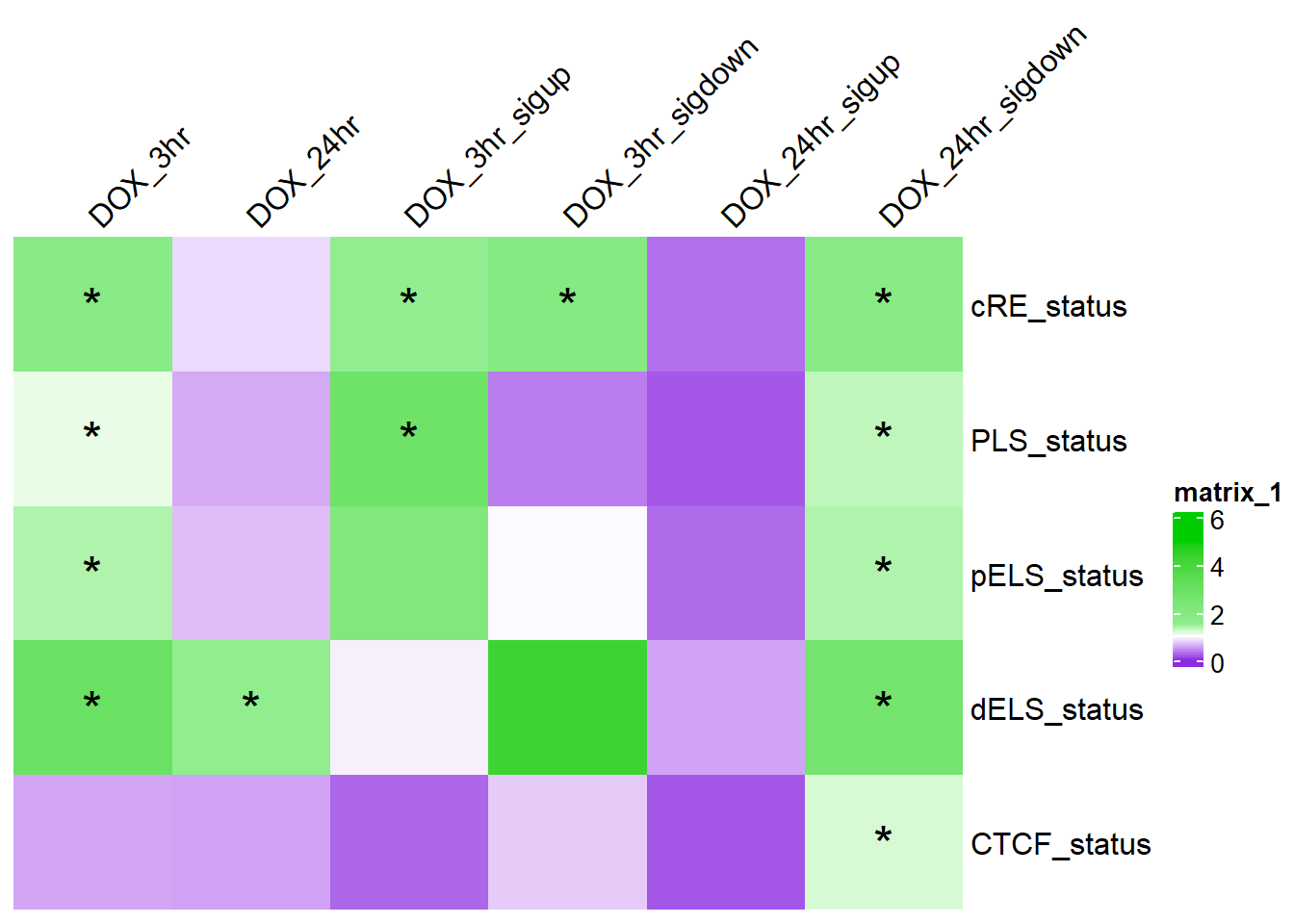
note, this is corrected for multiple testing across categories within each DOX-DAR column.
sessionInfo()R version 4.4.2 (2024-10-31 ucrt)
Platform: x86_64-w64-mingw32/x64
Running under: Windows 11 x64 (build 26100)
Matrix products: default
locale:
[1] LC_COLLATE=English_United States.utf8
[2] LC_CTYPE=English_United States.utf8
[3] LC_MONETARY=English_United States.utf8
[4] LC_NUMERIC=C
[5] LC_TIME=English_United States.utf8
time zone: America/Chicago
tzcode source: internal
attached base packages:
[1] grid stats4 stats graphics grDevices utils datasets
[8] methods base
other attached packages:
[1] circlize_0.4.16
[2] epitools_0.5-10.1
[3] ggrepel_0.9.6
[4] plyranges_1.26.0
[5] ggsignif_0.6.4
[6] genomation_1.38.0
[7] smplot2_0.2.5
[8] eulerr_7.0.2
[9] biomaRt_2.62.1
[10] devtools_2.4.5
[11] usethis_3.1.0
[12] ggpubr_0.6.0
[13] BiocParallel_1.40.0
[14] scales_1.3.0
[15] VennDiagram_1.7.3
[16] futile.logger_1.4.3
[17] gridExtra_2.3
[18] ggfortify_0.4.17
[19] edgeR_4.4.2
[20] limma_3.62.2
[21] rtracklayer_1.66.0
[22] org.Hs.eg.db_3.20.0
[23] TxDb.Hsapiens.UCSC.hg38.knownGene_3.20.0
[24] GenomicFeatures_1.58.0
[25] AnnotationDbi_1.68.0
[26] Biobase_2.66.0
[27] GenomicRanges_1.58.0
[28] GenomeInfoDb_1.42.3
[29] IRanges_2.40.1
[30] S4Vectors_0.44.0
[31] BiocGenerics_0.52.0
[32] ChIPseeker_1.42.1
[33] RColorBrewer_1.1-3
[34] broom_1.0.7
[35] kableExtra_1.4.0
[36] lubridate_1.9.4
[37] forcats_1.0.0
[38] stringr_1.5.1
[39] dplyr_1.1.4
[40] purrr_1.0.4
[41] readr_2.1.5
[42] tidyr_1.3.1
[43] tibble_3.2.1
[44] ggplot2_3.5.1
[45] tidyverse_2.0.0
[46] workflowr_1.7.1
loaded via a namespace (and not attached):
[1] fs_1.6.5
[2] matrixStats_1.5.0
[3] bitops_1.0-9
[4] enrichplot_1.26.6
[5] doParallel_1.0.17
[6] httr_1.4.7
[7] profvis_0.4.0
[8] tools_4.4.2
[9] backports_1.5.0
[10] R6_2.6.1
[11] lazyeval_0.2.2
[12] GetoptLong_1.0.5
[13] urlchecker_1.0.1
[14] withr_3.0.2
[15] prettyunits_1.2.0
[16] cli_3.6.4
[17] formatR_1.14
[18] Cairo_1.6-2
[19] sass_0.4.9
[20] Rsamtools_2.22.0
[21] systemfonts_1.2.1
[22] yulab.utils_0.2.0
[23] foreign_0.8-88
[24] DOSE_4.0.1
[25] svglite_2.1.3
[26] R.utils_2.13.0
[27] sessioninfo_1.2.3
[28] plotrix_3.8-4
[29] BSgenome_1.74.0
[30] pwr_1.3-0
[31] impute_1.80.0
[32] rstudioapi_0.17.1
[33] RSQLite_2.3.9
[34] shape_1.4.6.1
[35] generics_0.1.4
[36] gridGraphics_0.5-1
[37] TxDb.Hsapiens.UCSC.hg19.knownGene_3.2.2
[38] BiocIO_1.16.0
[39] vroom_1.6.5
[40] gtools_3.9.5
[41] car_3.1-3
[42] GO.db_3.20.0
[43] Matrix_1.7-3
[44] abind_1.4-8
[45] R.methodsS3_1.8.2
[46] lifecycle_1.0.4
[47] whisker_0.4.1
[48] yaml_2.3.10
[49] carData_3.0-5
[50] SummarizedExperiment_1.36.0
[51] gplots_3.2.0
[52] qvalue_2.38.0
[53] SparseArray_1.6.2
[54] BiocFileCache_2.14.0
[55] blob_1.2.4
[56] promises_1.3.2
[57] crayon_1.5.3
[58] miniUI_0.1.2
[59] ggtangle_0.0.6
[60] lattice_0.22-6
[61] cowplot_1.1.3
[62] KEGGREST_1.46.0
[63] magick_2.8.7
[64] ComplexHeatmap_2.22.0
[65] pillar_1.10.2
[66] knitr_1.50
[67] fgsea_1.32.2
[68] rjson_0.2.23
[69] boot_1.3-31
[70] codetools_0.2-20
[71] fastmatch_1.1-6
[72] glue_1.8.0
[73] getPass_0.2-4
[74] ggfun_0.1.8
[75] data.table_1.17.0
[76] remotes_2.5.0
[77] vctrs_0.6.5
[78] png_0.1-8
[79] treeio_1.30.0
[80] gtable_0.3.6
[81] cachem_1.1.0
[82] xfun_0.51
[83] S4Arrays_1.6.0
[84] mime_0.12
[85] iterators_1.0.14
[86] statmod_1.5.0
[87] ellipsis_0.3.2
[88] nlme_3.1-167
[89] ggtree_3.14.0
[90] bit64_4.6.0-1
[91] filelock_1.0.3
[92] progress_1.2.3
[93] rprojroot_2.0.4
[94] bslib_0.9.0
[95] rpart_4.1.24
[96] KernSmooth_2.23-26
[97] Hmisc_5.2-2
[98] colorspace_2.1-1
[99] DBI_1.2.3
[100] seqPattern_1.38.0
[101] nnet_7.3-20
[102] tidyselect_1.2.1
[103] processx_3.8.6
[104] bit_4.6.0
[105] compiler_4.4.2
[106] curl_6.2.1
[107] git2r_0.35.0
[108] httr2_1.1.2
[109] htmlTable_2.4.3
[110] xml2_1.3.7
[111] DelayedArray_0.32.0
[112] checkmate_2.3.2
[113] caTools_1.18.3
[114] callr_3.7.6
[115] rappdirs_0.3.3
[116] digest_0.6.37
[117] rmarkdown_2.29
[118] XVector_0.46.0
[119] base64enc_0.1-3
[120] htmltools_0.5.8.1
[121] pkgconfig_2.0.3
[122] MatrixGenerics_1.18.1
[123] dbplyr_2.5.0
[124] fastmap_1.2.0
[125] GlobalOptions_0.1.2
[126] rlang_1.1.5
[127] htmlwidgets_1.6.4
[128] UCSC.utils_1.2.0
[129] shiny_1.10.0
[130] farver_2.1.2
[131] jquerylib_0.1.4
[132] zoo_1.8-13
[133] jsonlite_1.9.1
[134] GOSemSim_2.32.0
[135] R.oo_1.27.1
[136] RCurl_1.98-1.16
[137] magrittr_2.0.3
[138] Formula_1.2-5
[139] GenomeInfoDbData_1.2.13
[140] ggplotify_0.1.2
[141] patchwork_1.3.0
[142] munsell_0.5.1
[143] Rcpp_1.0.14
[144] ape_5.8-1
[145] stringi_1.8.4
[146] zlibbioc_1.52.0
[147] plyr_1.8.9
[148] pkgbuild_1.4.8
[149] parallel_4.4.2
[150] Biostrings_2.74.1
[151] splines_4.4.2
[152] hms_1.1.3
[153] locfit_1.5-9.12
[154] ps_1.9.0
[155] igraph_2.1.4
[156] reshape2_1.4.4
[157] pkgload_1.4.0
[158] futile.options_1.0.1
[159] XML_3.99-0.18
[160] evaluate_1.0.3
[161] lambda.r_1.2.4
[162] foreach_1.5.2
[163] tzdb_0.4.0
[164] httpuv_1.6.15
[165] clue_0.3-66
[166] gridBase_0.4-7
[167] xtable_1.8-4
[168] restfulr_0.0.15
[169] tidytree_0.4.6
[170] rstatix_0.7.2
[171] later_1.4.1
[172] viridisLite_0.4.2
[173] aplot_0.2.6
[174] memoise_2.0.1
[175] GenomicAlignments_1.42.0
[176] cluster_2.1.8.1
[177] timechange_0.3.0