Figure_S5
Last updated: 2025-08-10
Checks: 5 2
Knit directory: Paul_CX_2025/
This reproducible R Markdown analysis was created with workflowr (version 1.7.1). The Checks tab describes the reproducibility checks that were applied when the results were created. The Past versions tab lists the development history.
The R Markdown is untracked by Git. To know which version of the R
Markdown file created these results, you’ll want to first commit it to
the Git repo. If you’re still working on the analysis, you can ignore
this warning. When you’re finished, you can run
wflow_publish to commit the R Markdown file and build the
HTML.
Great job! The global environment was empty. Objects defined in the global environment can affect the analysis in your R Markdown file in unknown ways. For reproduciblity it’s best to always run the code in an empty environment.
The command set.seed(20250129) was run prior to running
the code in the R Markdown file. Setting a seed ensures that any results
that rely on randomness, e.g. subsampling or permutations, are
reproducible.
Great job! Recording the operating system, R version, and package versions is critical for reproducibility.
Nice! There were no cached chunks for this analysis, so you can be confident that you successfully produced the results during this run.
Using absolute paths to the files within your workflowr project makes it difficult for you and others to run your code on a different machine. Change the absolute path(s) below to the suggested relative path(s) to make your code more reproducible.
| absolute | relative |
|---|---|
| C:/Work/Postdoc_UTMB/CX-5461 Project/RNA Seq/Alignment/Paul_CX_2025/data/Total_number_of_reads_by_sample.csv | data/Total_number_of_reads_by_sample.csv |
Great! You are using Git for version control. Tracking code development and connecting the code version to the results is critical for reproducibility.
The results in this page were generated with repository version 45b363f. See the Past versions tab to see a history of the changes made to the R Markdown and HTML files.
Note that you need to be careful to ensure that all relevant files for
the analysis have been committed to Git prior to generating the results
(you can use wflow_publish or
wflow_git_commit). workflowr only checks the R Markdown
file, but you know if there are other scripts or data files that it
depends on. Below is the status of the Git repository when the results
were generated:
Ignored files:
Ignored: .RData
Ignored: .Rhistory
Ignored: .Rproj.user/
Ignored: 0.1 box.svg
Ignored: Rplot04.svg
Untracked files:
Untracked: analysis/Figure_S5.Rmd
Unstaged changes:
Deleted: analysis/Figure_S4.Rmd
Note that any generated files, e.g. HTML, png, CSS, etc., are not included in this status report because it is ok for generated content to have uncommitted changes.
There are no past versions. Publish this analysis with
wflow_publish() to start tracking its development.
📌 Total Reads by Sample
This section visualizes the total RNA-sequencing reads across samples.
Load Required Libraries
# Load necessary R packages
library(limma)Warning: package 'limma' was built under R version 4.3.1library(RColorBrewer)
library(data.table)Warning: package 'data.table' was built under R version 4.3.3library(tidyverse)Warning: package 'tidyverse' was built under R version 4.3.2Warning: package 'tidyr' was built under R version 4.3.3Warning: package 'readr' was built under R version 4.3.3Warning: package 'purrr' was built under R version 4.3.3Warning: package 'dplyr' was built under R version 4.3.2Warning: package 'stringr' was built under R version 4.3.2Warning: package 'lubridate' was built under R version 4.3.3── Attaching core tidyverse packages ──────────────────────── tidyverse 2.0.0 ──
✔ dplyr 1.1.4 ✔ readr 2.1.5
✔ forcats 1.0.0 ✔ stringr 1.5.1
✔ ggplot2 3.5.2 ✔ tibble 3.2.1
✔ lubridate 1.9.4 ✔ tidyr 1.3.1
✔ purrr 1.0.4
── Conflicts ────────────────────────────────────────── tidyverse_conflicts() ──
✖ dplyr::between() masks data.table::between()
✖ dplyr::filter() masks stats::filter()
✖ dplyr::first() masks data.table::first()
✖ lubridate::hour() masks data.table::hour()
✖ lubridate::isoweek() masks data.table::isoweek()
✖ dplyr::lag() masks stats::lag()
✖ dplyr::last() masks data.table::last()
✖ lubridate::mday() masks data.table::mday()
✖ lubridate::minute() masks data.table::minute()
✖ lubridate::month() masks data.table::month()
✖ lubridate::quarter() masks data.table::quarter()
✖ lubridate::second() masks data.table::second()
✖ purrr::transpose() masks data.table::transpose()
✖ lubridate::wday() masks data.table::wday()
✖ lubridate::week() masks data.table::week()
✖ lubridate::yday() masks data.table::yday()
✖ lubridate::year() masks data.table::year()
ℹ Use the conflicted package (<http://conflicted.r-lib.org/>) to force all conflicts to become errorslibrary(scales)Warning: package 'scales' was built under R version 4.3.2
Attaching package: 'scales'
The following object is masked from 'package:purrr':
discard
The following object is masked from 'package:readr':
col_factorlibrary(ggplot2)
library(dplyr)📍 2. Load Data
# Load the dataset containing the total reads per sample
align <- read.csv("C:/Work/Postdoc_UTMB/CX-5461 Project/RNA Seq/Alignment/Paul_CX_2025/data/Total_number_of_reads_by_sample.csv") # Ensure the file is in the 'data/' folder
map <- data.frame(align)📍 3. Define Color Palettes
# Define color palettes for plots
drug_palc <- c("#8B006D","#DF707E","#F1B72B", "#3386DD","#707031","#41B333")
Ind_palc <- c("#ffbe0b","#ff006e","#fb5607", "#8338ec","#3a86ff","#4a4e69")
Time_palc <- c("#0000FF","#80FF00", "#FF00FF")
Combined_palc <- c("#FF0000","#00FF00","#0000FF","#FFFF00","#FF00FF","#00FFFF",
"#FFA500","#800080","#FFC0CB","#A52A2A","#808080","#FFD700",
"#008080","#000080","#FFFFFF","#000000","#D2691E","#ADFF2F")📍 4. Prepare Data
# Factor Sample_name to maintain order
map$Sample_name <- factor(map$Sample_name, levels = map$Sample_name)📍 5. Plot Total Reads by Sample
# Generate the bar plot
p <- ggplot(map, aes(x = Sample_name, y = Counts, fill = Condition)) +
geom_col() +
scale_fill_manual(values = drug_palc) +
scale_y_continuous(labels = function(x) paste0(x / 1e6, "M")) +
ggtitle(expression("Total number of reads by sample")) +
xlab("") +
ylab(expression("RNA-sequencing reads")) +
theme_bw() +
theme(
plot.title = element_text(size = rel(2), hjust = 0.5),
axis.title = element_text(size = 15, color = "black"),
axis.ticks = element_line(linewidth = 1.5),
axis.line = element_line(linewidth = 1.5),
axis.text.y = element_text(size = 10, color = "black", angle = 0, hjust = 0.8, vjust = 0.5),
axis.text.x = element_text(size = 10, color = "black", angle = 90, hjust = 1, vjust = 0.2)
)
# Save the plot as an image
ggsave("output/total_reads_by_sample_plot.png", p)
# Display the plot in the document
p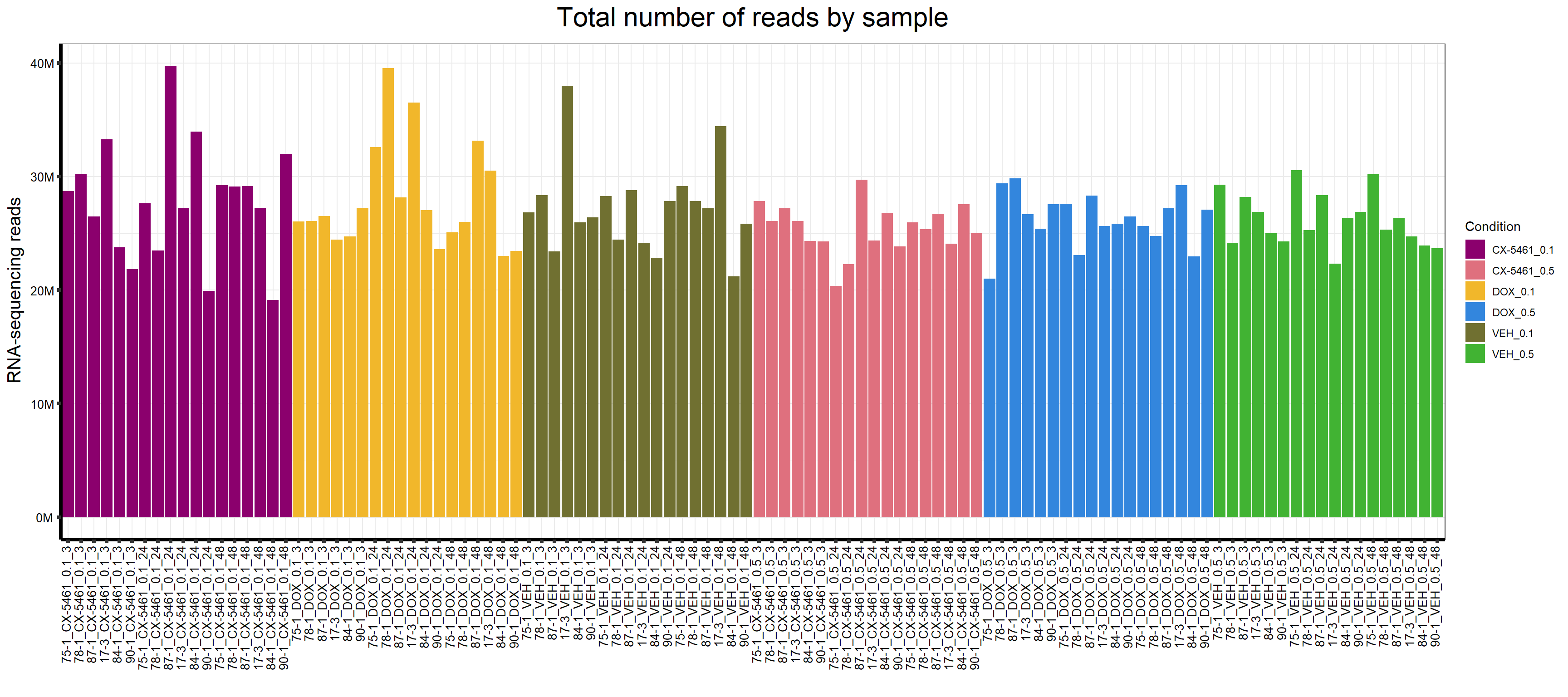
📌 Total Reads by Treatment
📍 Define Color Palettes
# Define color palettes for plots
drug_palc <- c("#8B006D","#DF707E","#F1B72B", "#3386DD","#707031","#41B333")
Ind_palc <- c("#ffbe0b","#ff006e","#fb5607", "#8338ec","#3a86ff","#4a4e69")
Time_palc <- c("#0000FF","#80FF00", "#FF00FF")
Combined_palc <- c("#FF0000","#00FF00","#0000FF","#FFFF00","#FF00FF","#00FFFF",
"#FFA500","#800080","#FFC0CB","#A52A2A","#808080","#FFD700",
"#008080","#000080","#FFFFFF","#000000","#D2691E","#ADFF2F")📍 Load dataset for total reads by treatment
align1 <- read.csv("C:/Work/Postdoc_UTMB/CX-5461 Project/RNA Seq/Alignment/Paul_CX_2025/data/Total_number_of_reads_by_sample.csv") # Ensure this file is inside the 'data/' folder
map1 <- data.frame(align1)📍 Generate the boxplot
p_treatment <- ggplot(map1, aes(x = Condition, y = Counts, fill = Condition)) +
geom_boxplot() +
scale_fill_manual(values = drug_palc) +
scale_y_continuous(
limits = c(0, 40000000), # Set y-axis range
labels = function(x) paste0(x / 1e6, "M") # Display labels in millions
) +
ggtitle(expression("Total number of reads by treatment")) +
xlab("") +
ylab(expression("RNA-sequencing reads")) +
theme_bw() +
theme(
plot.title = element_text(size = rel(2), hjust = 0.5),
axis.title = element_text(size = 15, color = "black"),
axis.text.x = element_text(size = 10, angle = 90, hjust = 1, vjust = 0.2)
)
# Save the plot as an image
ggsave("output/total_reads_by_treatment_plot.png", p_treatment)
# Display the plot in the document
p_treatment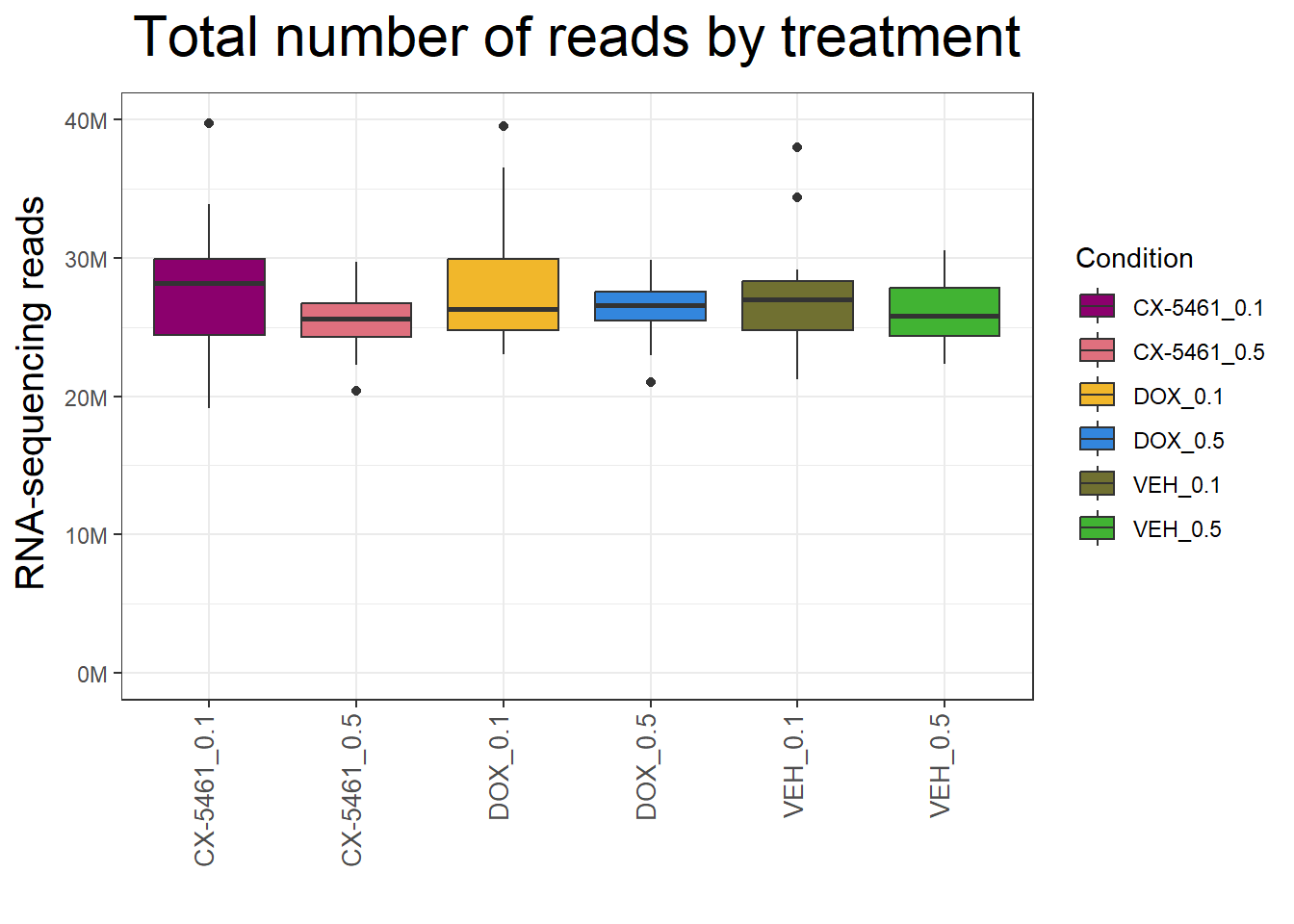
📌 Total Reads by Time
📍 Define Color Palettes
# Define color palette for time points
Time_palc <- c("#0000FF","#80FF00", "#FF00FF")📍 Load dataset for total reads by time
# Load dataset for total reads by time
align3 <- read.csv("data/Total_number_of_reads_by_time.csv") # Ensure this file is inside the 'data/' folder
map3 <- data.frame(align3)📍 Generate the boxplot
# Generate the boxplot
p_time <- ggplot(map3, aes(x = Condition, y = Counts, fill = Time)) +
geom_boxplot() +
scale_fill_manual(values = Time_palc) +
scale_y_continuous(
limits = c(0, 40000000), # Set y-axis range
labels = function(x) paste0(x / 1e6, "M") # Display labels in millions
) +
ggtitle(expression("Total number of reads by time")) +
xlab("") +
ylab(expression("RNA-sequencing reads")) +
theme_bw() +
theme(
plot.title = element_text(size = rel(2), hjust = 0.5),
axis.title = element_text(size = 15, color = "black"),
axis.text.x = element_text(size = 10, angle = 90, hjust = 1, vjust = 0.2)
)
# Save the plot as an image
ggsave("output/total_reads_by_time_plot.png", p_time)
# Display the plot in the document
p_time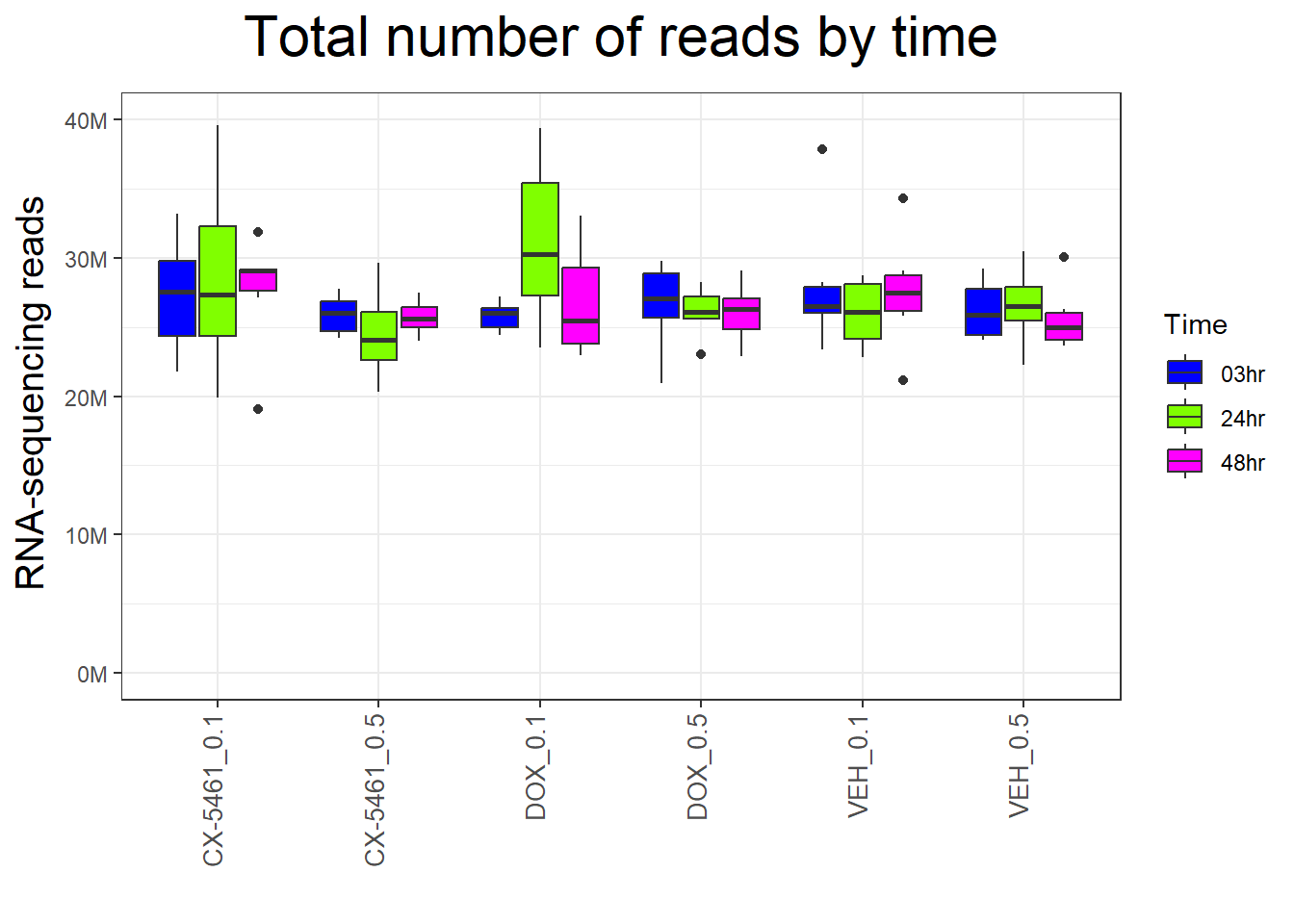
sessionInfo()R version 4.3.0 (2023-04-21 ucrt)
Platform: x86_64-w64-mingw32/x64 (64-bit)
Running under: Windows 11 x64 (build 26100)
Matrix products: default
locale:
[1] LC_COLLATE=English_United States.utf8
[2] LC_CTYPE=English_United States.utf8
[3] LC_MONETARY=English_United States.utf8
[4] LC_NUMERIC=C
[5] LC_TIME=English_United States.utf8
time zone: America/Chicago
tzcode source: internal
attached base packages:
[1] stats graphics grDevices utils datasets methods base
other attached packages:
[1] scales_1.3.0 lubridate_1.9.4 forcats_1.0.0 stringr_1.5.1
[5] dplyr_1.1.4 purrr_1.0.4 readr_2.1.5 tidyr_1.3.1
[9] tibble_3.2.1 ggplot2_3.5.2 tidyverse_2.0.0 data.table_1.17.0
[13] RColorBrewer_1.1-3 limma_3.58.1
loaded via a namespace (and not attached):
[1] sass_0.4.10 generics_0.1.3 stringi_1.8.3 hms_1.1.3
[5] digest_0.6.34 magrittr_2.0.3 evaluate_1.0.3 grid_4.3.0
[9] timechange_0.3.0 fastmap_1.2.0 rprojroot_2.0.4 workflowr_1.7.1
[13] jsonlite_2.0.0 promises_1.3.2 textshaping_1.0.0 jquerylib_0.1.4
[17] cli_3.6.1 rlang_1.1.3 munsell_0.5.1 withr_3.0.2
[21] cachem_1.1.0 yaml_2.3.10 tools_4.3.0 tzdb_0.5.0
[25] colorspace_2.1-0 httpuv_1.6.15 vctrs_0.6.5 R6_2.6.1
[29] lifecycle_1.0.4 git2r_0.36.2 fs_1.6.3 ragg_1.4.0
[33] pkgconfig_2.0.3 pillar_1.10.2 bslib_0.9.0 later_1.3.2
[37] gtable_0.3.6 glue_1.7.0 Rcpp_1.0.12 systemfonts_1.2.2
[41] statmod_1.5.0 xfun_0.52 tidyselect_1.2.1 rstudioapi_0.17.1
[45] knitr_1.50 farver_2.1.2 htmltools_0.5.8.1 labeling_0.4.3
[49] rmarkdown_2.29 compiler_4.3.0